
Tokens are not kWs
And what changes when the input gets legible
The line keeps showing up in Sam Altman’s talks. “We see a future where intelligence is a utility, like electricity or water, and people buy it from us on a meter.” BlackRock’s Infrastructure Summit, interviews, investor calls. He has settled into the analogy and the analogy has settled into him. OpenAI is becoming a utility company, the next big infrastructure layer, water and power and tokens.
The analogy is doing something useful. It makes tokens legible as an input, not as a product. For two years the labs have been describing what they sell as “intelligence” or “AGI” or “the smartest model,” all of which are product framings that imply you should pay for the thing itself. The utility framing flips that. Tokens are an input. You consume them to produce something else, something that normally would have required some cognitive work. That is the right intuition, and once you take it seriously the economics of AI look different than the labs have been telling us.
The analogy also carries baggage that does not fit.
What makes a utility a utility
Utilities have inelastic demand. You need electricity to keep your fridge running. You need water to live. You do not shop for kilowatts on Tuesday morning. You pay whatever the bill says, and you keep paying because there is no version of your life where you stop. The product is not amazing, you simply cannot say no.
The other thing that makes utilities work is that the commodity is fungible. A kilowatt-hour is a kilowatt-hour. Solar, coal, nuclear, hydro, it makes no difference once it reaches your meter. The meter is meaningful because both sides agree on what the unit is, and the unit is the same regardless of who supplied it. That fungibility is what makes the wholesale markets work, what lets the regulators set rates, and what makes the entire utility business model legible to investors.
Tokens are not like that.
A token from GPT-5 is not a token from Claude 4.5 is not a token from DeepSeek V4. Different tokenizers literally cut the world into different units. A 1,000-token answer from one model is not the same workload as a 1,000-token answer from another. The same task can take 800 tokens in one model and 4,500 in another, at radically different quality. Ten words from Richard Feynman are not the same as ten words from a corporate lawyer. The count is identical, the value is not. There is an underlying hidden metric to the token that represents the actual value per token, and the bill does not show it. The unit, on its own, tells you nothing.
The utility framing depends on the unit being legible. The unit is not legible.
Tokens are a factor of production
The useful thing the utility framing does is name what tokens actually are. They are an input, the same way crude is an input to a refinery. You buy them, you transform them, you sell the output. The token is not the product. The token is the raw material you use to make the product.
This is the frame I have been working through for a while, including in the differentiation-then-commoditization piece a few months ago. The core dynamic is per-JTBD, not per-model-release. For any given job that AI might be able to do, there is an exploration window during which the question is whether AI can do it at all. In that window people will pay premium prices to find out. They will use the frontier model for the translation prototype, the customer-support agent prototype, the contract-review prototype. The premium is rational because the question being answered is binary. Does this work, yes or no.
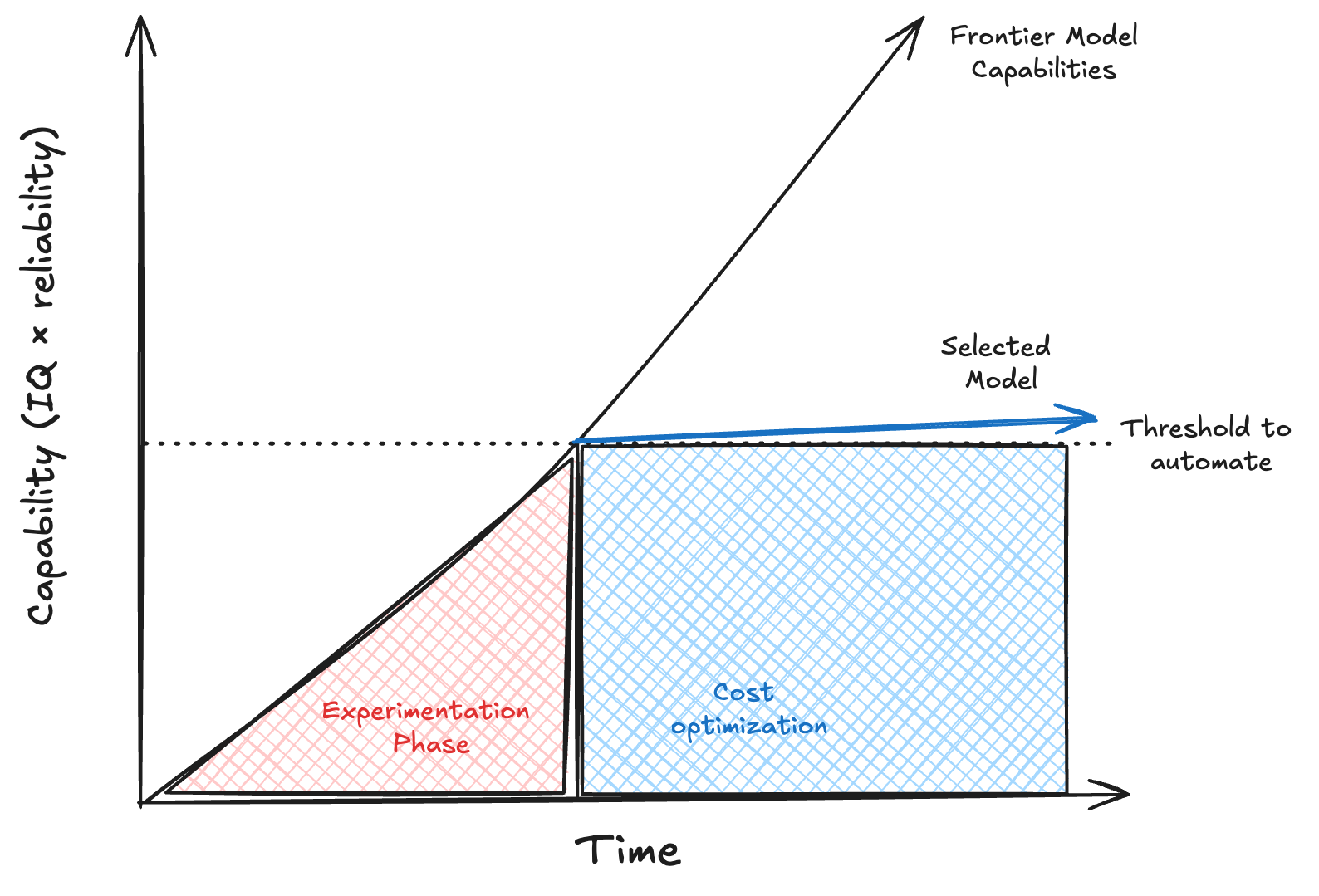
Once the answer is yes, the question changes from “can it work” to “what is the cheapest input that clears the bar.” That is when the JTBD commoditizes. Capability unlocks new JTBDs, and that unlock window is real. But every specific job that crosses the works-doesn’t-work line commoditizes fast inside its own track. Nobody uses GPT-5.5 for translation in 2026. Translation works on a much smaller model that runs at a fraction of the price, and the procurement decision is made on cost.
This is what makes the utility framing partially right. In the commoditization phase a given JTBD really does behave like a commodity input. Multiple providers, real substitutability on the outputs that meet the bar, a buyer who shops on price-per-outcome. That is commodity behavior. The token in that phase is meaningfully a factor of production, not a product. The utility analogy gets the input nature right.
It misses everywhere else.
The phase the consumer market is already in
A lot of the common consumer JTBDs are already in the commoditization phase. The capability is there, the optimization question has been answered, the frontier does not earn a premium for them anymore. This is the capability overhang I have been writing about in Gap of Imagination. The frontier keeps building capability that ordinary users cannot even imagine an application for. The premium that flows to the frontier today is partly flowing because the labs keep redefining the JTBD bar, not because users are running into capability ceilings on the things they actually want done. In simple terms, you give people an advanced agent and they ask for a selfie.
Demand keeps moving to the frontier because the labs need it to. Sam saying “the demand keeps surprising me, people always want the smartest model” is a true description of the demand curve and an incomplete description of why it looks the way it does. There is a world in which most JTBDs reach the commoditization phase and tokens behave like a real commodity market, priced near marginal cost with arbitrage running through everything routine. In that world there is still a tier of work where the value per token is enormous and the bill barely registers. Curing a category of cancer is the canonical example, the kind of problem where the answer is worth so much that asking how many tokens it took is the wrong question. Pricing a derivative nobody else priced correctly, discovering a material that does not exist yet, finding the next class of drug. Those JTBDs do not commoditize the way translation did. The labs and companies that learn to direct token spend at them are not playing the same game as everyone else routing the cheap stuff through Claude Haiku.
The labs know this, which is why their biggest product bets are not at the model layer anymore.
What this means for AGI labs
If tokens are a factor of production and the JTBD-by-JTBD commoditization is real, the closest historical analog for the labs is the oil majors. Large by revenue, thin by margin, with the value compounding through volume rather than through pricing power. ExxonMobil is one of the most consequential companies of the last century and its operating margin per barrel is unremarkable.
This is not bad news for the labs. It is just a different kind of business than the utility pitch implies. I wrote a few weeks ago in Of AI Bubbles and Token Explosions that token demand in the agentic era is going to grow by several orders of magnitude. Jevons paradox plus zero human bottleneck plus collapsing per-token cost compound into a demand curve steeper than almost anyone has modeled. The more I use and deploy agents the more I think this is true. I am already burning hundreds of millions of tokens every day, and the reason I do not run even more agentic flows is cost and time, not a shortage of use cases. That will happen to the rest of us. The build-up is justified. The labs are going to be enormous companies. They will be enormous in the way oil majors are enormous.
What they will not be is high-margin at the model layer. The surplus per task completed with tokens, which is the spread between marginal cost and marginal product, accrues to whoever owns the relationship with the user. The labs build the volume side. The application layer captures the spread.
Which is exactly why every major lab is climbing up-stack as aggressively as they can ship. Operator, Codex, Atlas, Sora, the apps platform, ChatGPT for Business. None of these are model-layer products, and for sure they are not what you would expect from a token factory. All of them are bets on owning the application layer where the surplus lives. The investor pitch is utility-shaped because utility-shaped capex needs a utility-shaped story. Sam’s repeated “intelligence is a utility” line is positioning, not analysis. The actual business plan is to capture the surplus up-stack before somebody else does. Right now, that front is enterprise. The utility pitch is the financing strategy. The aggressive up-stack push is the business strategy. They are not the same thing, and watching the products instead of the press release is the only way to see which is real.
What this means for companies buying tokens
If you are on the buying side of the meter rather than the selling side, the production-input frame has direct implications.
Almost every AI subscription you pay for today is subsidized. ChatGPT Plus, Claude Pro, the Bedrock and Vertex offerings, all of them are priced below what the actual workload costs to serve (the difference shows up on someone’s balance sheet, just not yours). The labs are eating the gap to acquire user habit, lock in workflow integration, and prove a category at scale. You are paying $20/200 a month right now because someone with capital wants you to.
That subsidy ends. The path is visible. OpenAI has no ultra developer plan, they want you on the API key (the meter). When the subsidy actually ends, every company that grew used to a $20-per-seat AI bill is going to discover that the real cost of the workload is several times that, and the convenience tax was the lab eating the difference to keep them locked in. That is also the moment tokens become legibly what they always were. A production input, with a price that has to be procured for instead of subscribed to.
The value of the tokens is very high, don’t get me wrong, which means that the companies that survive that transition are the ones who built denominator discipline early. Your token bill alone tells you nothing. Tokens per resolved ticket, tokens per closed sale, tokens per generated brief, those are the units that matter when the meter starts charging the real number. The same applies on the supplier side. The lab that costs ten times more per token is not necessarily ten times more expensive for your workload, and the only way to know is to have the denominator.
Two things to be working on now, while the era is still subsidized. First, build for swappability. The provider you start with should not be the provider you end up locked into. The orchestration layer or harness between your product and the model has to be thin enough that swapping suppliers is a configuration change, not a refactor. Every prompt format, tokenizer assumption, or function-calling convention you embed deep in your code is a switching cost the supplier collects later. Second, track outcomes per dollar, not tokens per request. Build the denominator now, while the bill is small and the room to instrument is generous.
When the subsidy ends, the companies that did this work keep their AI cost lines healthy. The ones that waited discover they spent two years embedding one supplier into the foundations of their product, and the bill is now arriving at the unsubsidized price.
The labs’ incentive is to make the meter spin faster. Yours is to extract the most outcome per unit of meter spin. Those two interests are not aligned, and that is what the utility framing is hiding.
The labs are commodity producers learning to live with commodity economics. The companies buying their output are consumers of a production input who have not started procuring it like one. Sam Altman’s utility framing is half-right about the thing that matters most. Tokens really are becoming a factor of production, and that framing is the cleanest one anyone in his position has put out loud. The half he had to leave out is that factor-of-production economics are not utility economics, and the businesses that grow on each side of the meter will be very different from what the pitch deck suggests.
Tokens are not kWs, at least for most of us.