
Of AI Bubbles and Token Explosions
Token consumption, the staircase, and the math behind the next 1,000x
In my last post I wrote about what it feels like to build with AI agents at full intensity. This one is about the number behind that feeling, and why it convinced me this isn't a bubble.
Last Friday I burned 800 million tokens in a day, or to make it into a tangible amount, I produced the equivalent of 1,600 Don Quijotes. A year ago, that would have taken months. Two years ago, I wouldn’t have attempted it.
The Staircase
When Luzia was five people meeting in a cleaning company in Albacete (long way from there), I drew a chart for our very first all-hands that explained our mission as a company.
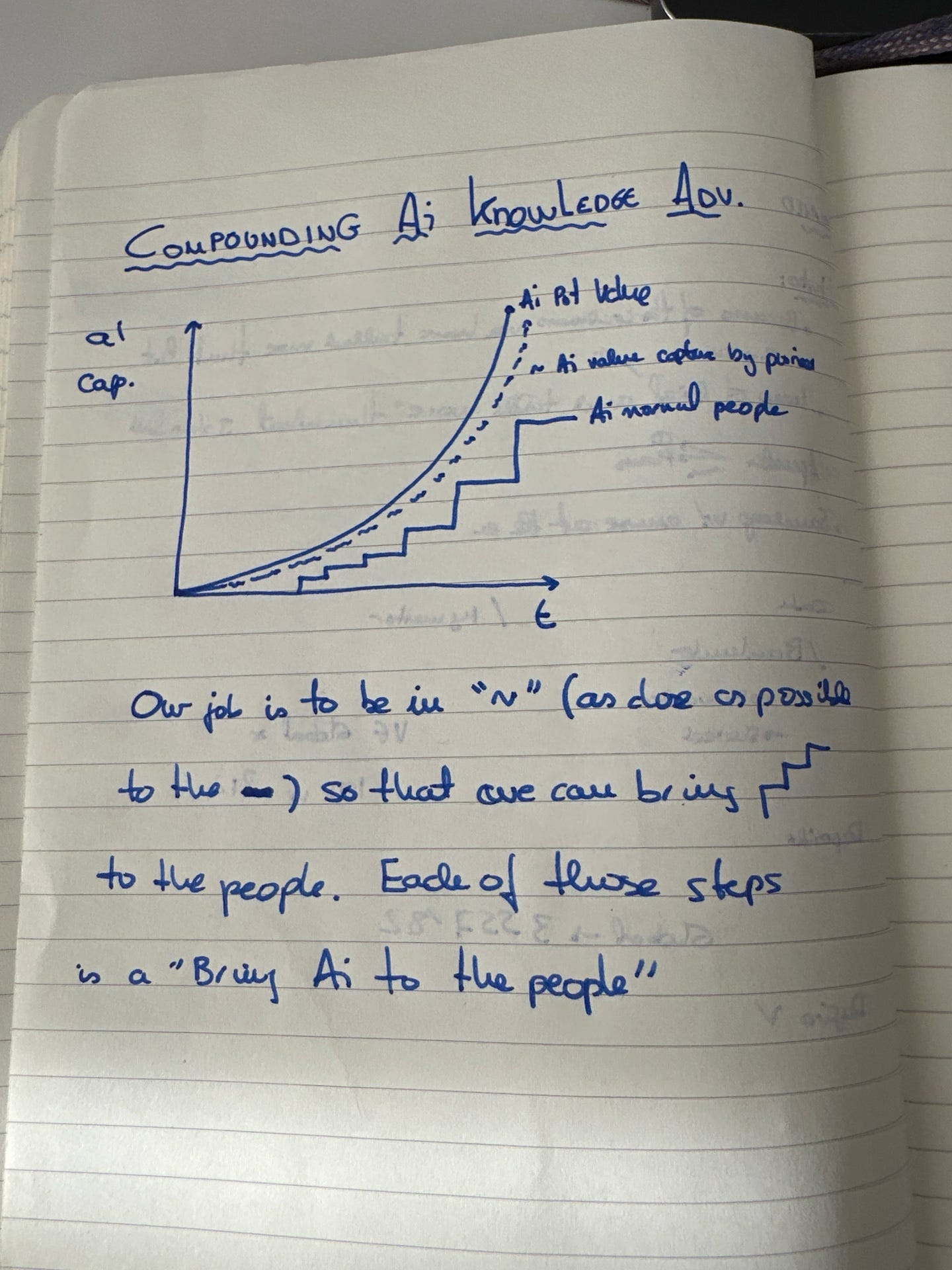
The idea behind it is something I’ve been thinking about a lot lately, how most people can’t picture what AI can actually do for them, so they never ask for it. This chart was the first version of that idea. Two lines: the AI frontier, which grows exponentially, and people’s adoption, which grows in steps. Our job is to stay as close to the frontier as possible so we can pull the staircase up.
Those steps map cleanly to token count. Each generation of AI technology adds a zero to your consumption.
~0 tokens. Most of humanity. Roughly 70-80% of the world. They’ve heard about AI, they have not experienced it.
~1K tokens per session. You open ChatGPT or Luzia, ask it to write an email, close the tab. About 20% of the population. 2023 technology.
~10K tokens per session. Reasoning models. For the first time the models could actually think and self-correct, and the use of tools (grounding, web search, documents) made AI genuinely useful for real work. Unfortunately, until DeepSeek broke open reasoning, most of these capabilities were locked behind paywalls, and as I’ve written before, most people don’t pay for AI. So the majority of users have never experienced what a thinking model can do. Maybe 10% of AI users are here. 2024 technology.
~100K tokens per session. Agentic coding, with capabilities that go well beyond coding. Claude Code, Codex. You stop writing prompts and start describing systems. You give the agent a goal, it plans the steps, writes the code, runs it, checks if it works, fixes what’s broken, and comes back when it’s done. You go make coffee. About 1% of people. 2025 technology.
~100M+ tokens per session. Autonomous agents running in parallel, building and testing and deploying while you sleep. You become the bottleneck, and the more you get out of the way, the more gets done. I wrote about what that feels like in my burnout post. The percentage of the population here rounds to zero.
Each step up, the number of people shrinks while consumption per person goes up by orders of magnitude.
Measuring the Gap
At Luzia we serve millions of users across Latin America. Most of them are on that first step, asking questions, translating text, getting help with homework. Real value, but our average user consumes maybe 1,000 tokens per session. I consumed 800 million in a day. That ratio, roughly 1 to 800,000, is the imagination gap expressed as a number.
Karpathy said something on the No Priors podcast recently that stuck with me. He talked about personal token throughput as the new measure of leverage, and that the question now is “what token throughput do you command?”
Your personal token consumption is a rough but real proxy for how much value you’re extracting from AI. If you’re at 0, AI doesn’t exist for you. If you’re at 1,000 tokens a day, it’s a fancy search engine. If you’re at 100 million, then we are talking. The gap between those two isn’t just quantitative, it’s a completely different relationship with the technology.
The Math
I love back-of-the-envelope calculations. They’re wildly inaccurate, but good for perspective.
You can actually estimate global token consumption from the staircase. Take the roughly 8 billion people on the planet, apply the percentages from each step, multiply by their average daily token use, and you get somewhere around 10-20 trillion tokens per day from direct human usage. Add enterprise API calls, batch processing, internal tools, and you’re in the neighborhood of 100 trillion tokens per day, which lines up with what the big providers are reporting (Google went from 9.7 trillion tokens/month to 480 trillion in a single year).
Now imagine a world where everyone moves up the staircase. Not to where I am, just to 1 million tokens per day, which is a moderate step 4. With 5 billion people (conservative), that’s 5,000 trillion tokens per day from humans alone. Add agents talking to agents, orchestration overhead, retries, tool calls, at a 10x multiplier, and you’re somewhere around 50,000 to 100,000 trillion tokens per day.
Today we do 100 trillion. That world needs 1,000 times more, and we are, if reports are true, using close of 100% of installed capacity.
All the words humanity has ever written, every book, every website, every email, every text message, adds up to roughly 130 trillion tokens. Once everyone has a real AI assistant, we’d burn through all of that in minutes.
And tokens cost energy. I went deep on this back in 2024, and the numbers have only gotten more intense. Even with 100x efficiency gains (aggressive by any measure), that level of consumption needs about 1 TW of continuous power. That’s 50-100 nuclear power plants dedicated to inference alone. It’s why every hyperscaler is buying nuclear and why Alphabet committed $175B+ in CapEx for 2026.
This Is Not a Bubble
A founder of an AI company saying “this is not a bubble” is about as credible as a hair dresser telling you that you need a haircut. I’m biased and I know it. I wrote about the bubble question back in August 2024, and my answer then was “it depends.” Eighteen months later, I have a clearer view.
The bubble argument usually rests on two things: the amount of CapEx going into AI infrastructure, and the lack of realized business value so far (MIT’s GenAI Divide report found that 95% of corporate AI pilots fail to deliver ROI). Simplified: AI needs mass adoption to justify the spend, and people are clearly not there yet.
That was a reasonable worry in 2024 or even in 2025. Agent harnesses changed the equation, starting with Claude Code and continuing with OpenClaw and Cowork. You don’t need that many people using AI effectively for demand to go through the roof. I’m one person. I burned 800 million tokens in a day, the equivalent of 800,000 users at step one of the staircase. And that's only comparing against the 20% who use AI at all. For the other 6 billion people, the number is zero. One person at the top of the staircase generates more demand than most of humanity combined1
There will be corrections along the way. There always are. But calling this a bubble misreads where the demand is coming from. It’s not hype cycles or consumer excitement. It’s agents that multiply compute by 10x or 100x per task, and companies restructuring around them because the economics are too compelling to ignore. As I wrote in my predictions post, things in AI stay hard until they don’t, and when the flip comes, it is not gradual.
My worry isn’t about whether the demand is real. It’s about who gets access. If the supply side keeps up, everyone eventually gets their million daily tokens. If demand outruns supply, tokens stay abundant for those who can pay and scarce for everyone else. That version hits emerging markets hardest, the ones Luzia serves, the ones I care about most.
Less Than 1%
I wrote in The Year to Push that the gap between where you are and where the best AI users are is still closeable. That’s still true. But the window gets shorter every month, because the top of the staircase keeps moving up.
We are at less than 1% of the progress bar. The math says we’re three orders of magnitude from stabilization. I burned 1,600 Quijotes in a day, and I’m one person.
Imagine when that’s normal.
80% of 8 billion = 6.4 billion people at zero tokens per day. Combined output: zero. The remaining 20%, about 1.6 billion, average roughly 1,000 tokens each, for a combined 1.6 trillion tokens per day. My 800 million is the equivalent of 800,000 of those active users, or 0.05% of all of them. Against the 6.4 billion? You can't divide by zero.