
Multimodal Autoregressive Models and a New Way to Creativity
The tech that's making AI-generated images practical
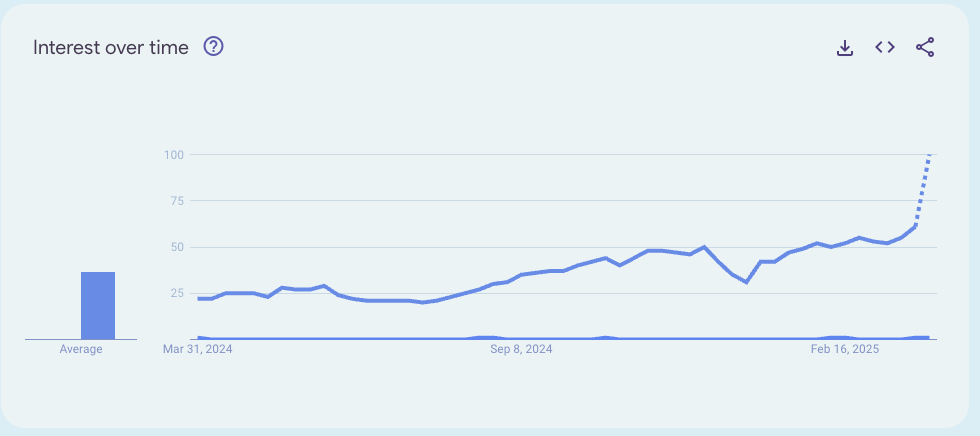
If you have been alive the last couple of weeks, you have almost certainly come across one manga-style image of your friend with a nice-looking dog or a re-version of your son’s picture as an astronaut, and I need to confess that I have been part of the trend.

These images come from a viral trend that started with the release of GPT-4o image generation on March 25th, a release that, I would argue, is bringing AI-generated photos back to the zeitgeist1.
I delayed writing this post over a week for two reasons, one I have been busy, two, and more importantly, I wanted to not focus on the hype, but focus on how the technology works and the implications going forward.
My main argument here is that GPT-4o's breakthrough isn't higher-quality images - they are good but not the best-, but its control and flexibility. This combination will unlock entirely new practical ways of using AI imagery.
Creating images, one token at a time.
From a technical standpoint, the key difference between GPT-4o image generation and other models such as Stable Diffusion (SD for short) or Flux (the one we use at Luzia) is that GPT generates images one token at a time, always considering previously generated tokens, in the same way GPT generates text.
To grasp the implications and advantages, let’s first take a step back and understand the current state-of-the-art in image generation.
Diffusion models
Most image generation models that had some relevance in the last 2.5 years were diffusion models. Diffusion models start from random noise—imagine static on an old TV—and gradually turn that noise into a clear, detailed image, step by step. It’s like watching a picture slowly emerge from chaos. Think of diffusion models as sculptors starting with a rough block of marble. They slowly chip away stone, refining the image bit by bit until a recognizable picture finally appears.

The process is reversed in training—you start by giving the model a perfectly defined image, then add a bit of random noise each time and ask the model to reconstruct it. Repeat this millions of times, and your model learns to create images. The key here is that the model works in the whole image the whole time2.

Over time, the quality of images generated by diffusion models has improved dramatically. Today, state-of-the-art diffusion models like Stable Diffusion XL or Imagen can produce images that feel strikingly realistic, not only visually, but also capturing subtleties such as natural lighting, textures, and even implicit physics.


Diffusion models have notable advantages—they’re cheaper to train and run than autoregressive alternatives, explaining why new ones pop up constantly. Yet, their critical drawback remains a lack of predictable control. This unpredictability prevents wider adoption, causing many casual users to abandon image generation after a few disappointing attempts. We've experienced this firsthand in Luzia: curious users see impressive images, experiment briefly, fail to recreate that magic, and rarely return. Chatbots avoided this fate by reliably meeting user needs with predictable, consistent interactions, highlighting the importance of control in AI adoption.
Autoregressive models
OpenAI’s approach to releasing its new image generation capabilities fundamentally differs from diffusion models—it relies on an autoregressive architecture. While that may sound technical, it simply means the model generates an image one small piece, or “token,” at a time, sequentially. Imagine typing out a paragraph letter-by-letter rather than printing the entire text simultaneously (like using a typewriter vs. a printing press). Each new token depends directly on the previous ones, much like predicting the next word in a sentence.
There have been rumors suggesting that GPT-4o might combine an initial autoregressive pass with a subsequent diffusion process, OpenAI’s official documentation indicates that GPT-4o’s image generation is purely autoregressive and does not incorporate diffusion models.
To visualize this, imagine building an image pixel by pixel, row by row, from top-left to bottom-right. Although OpenAI hasn't officially published all the details of GPT-4o’s architecture (OpenCloseAI), interestingly this approach mirrors what they initially explored with DALL-E 1 back in 2021, before diffusion models took the spotlight due to their lower computational costs and scalability.

But why bring autoregressive models back now? Two critical differences explain this:
Massive scaling: As always, more data, increased computing power, and smarter architectures dramatically improve performance. Autoregressive models, once considered too costly and slow, have become feasible at scale. Scaling up autoregressive models enhances their performance across various tasks, including text-to-image generation and multimodal understanding.
Multimodal integration: GPT-4o is part of an “omni” or multimodal family, meaning it uses a unified “embedding space” where text, images, and even audio coexist as numerical vectors. Imagine a massive three-dimensional space where every concept—words, images, sounds—is represented as a point, grouped by similarity. Because GPT-4o understands this shared space, it seamlessly bridges modalities, enabling richer interactions and greater coherence.
Let’s explore this idea of embedding space. Although it’s a technical concept, it’s also one of the most beautiful ones (at least in my view).
Embedding space
We’ve briefly touched on embedding spaces in previous posts, but let’s deepen our intuition a bit further. At its core, an embedding space is simply a mathematical way to represent information—words, images, or sounds—as points (vectors) in a continuous space. The closer two points are, the more similar their meanings or concepts.
Imagine plotting every word you know onto a huge map. Words like “cat” and “kitten” would cluster closely together, while “cat” and “spaceship” would sit far apart.
Now, consider multimodal embedding spaces—those that handle text, images, and audio simultaneously. Instead of just mapping words, imagine also adding visual and auditory concepts into this rich, multidimensional map. With more dimensions, the representation becomes even more precise.
But the cool thing is that with multimodality nuances matter (a lot!) The way you say something when working with multimodal embedding spaces affects where the token sits in this space. For instance, "hello" whispered softly won't land in the same spot as "HELLO!!!" shouted excitedly. This happens because multimodal embedding spaces don't just capture basic meaning; they also capture subtle differences like tone, emotion, and intensity. This allows the model to distinguish between subtle shades of meaning or emotion across modalities—like differentiating between the calm spoken word "hello," an excited wave in a video, and the written "HELLO!!!" with emojis.
Another powerful aspect of multimodality is scale. As we discussed in earlier posts, multimodal embeddings effectively expand the potential training dataset by bringing together diverse information sources—text, images, audio, and more. More data fuels better performance thanks to scaling laws, enabling models like GPT-4o to become smarter, more nuanced, and ultimately more useful.
What Makes This Approach Special?
Autoregressive image generation offers clear advantages compared to diffusion models, particularly predictability and control.
Since images are built token-by-token—much like how text is generated—the model has an easier time understanding context and adhering to specific instructions. This results in users experiencing more reliable, predictable outcomes, reducing the frustration of constantly refining prompts.
This connects nicely with another huge advantage: simplified prompting. Remember when the internet was convinced “Prompt Engineer” would become the hottest job title (I am so sorry for the 1000s of creators launching prompt engineering courses), and LinkedIn flooded with self-proclaimed “Prompt Ninjas”? Then GPT-4o (and even GPT-4) arrived, got smarter, and suddenly my typo-filled, barely coherent prompts still gave me exactly what you wanted, and no one talks about prompting anymore. We’re now seeing something similar with images: no more novel-length descriptions needed, no more tedious finger-counting. Just dump your thoughts—or better yet, a non-creative description—and it simply works.
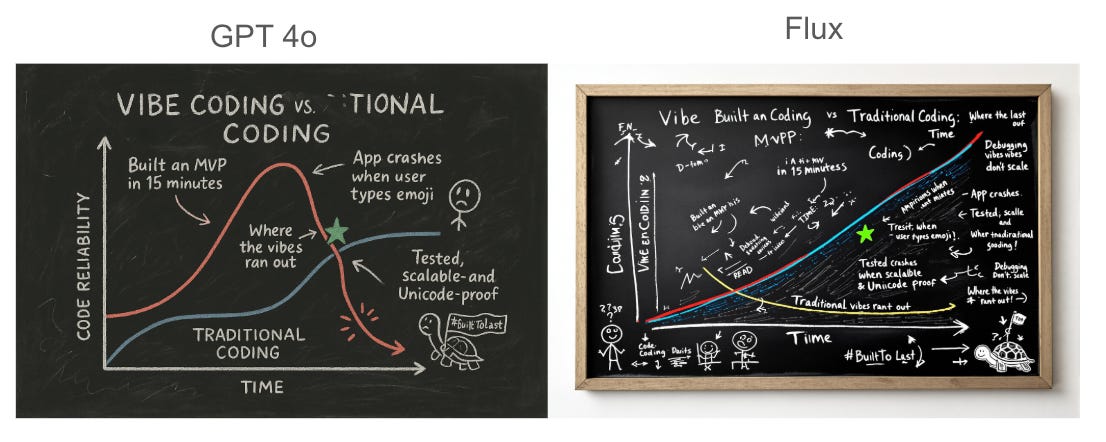
And as you can see with the example above, this gives users flexibility. The model can generate properly written text (and five-finger hands), infographics, and many other very useful illustrations.
The new multimodal models also shine in their ability to incrementally edit and generate images, meaning users can progressively refine or stylize them. You can take your kids’ pictures and easily transform them into Disney characters or Ghibli-style selfies simply by asking. This capability, previously cumbersome or unavailable with diffusion-based tools, is now seamless.
A final, subtler detail that I think has contributed to this model going viral is that, upon release, OpenAI significantly relaxed its moderation guidelines. Users can now generate images of known people or specific styles more freely. Why does this matter? It’s two-fold: first, x.com quickly filled with fun memes featuring Trump and other famous figures; second—and more importantly—fewer limitations mean greater user control. Few things are more annoying than advanced voice modes responding, “My guidelines don’t allow me to do this,” to even the simplest requests.3

While this increased flexibility enhances usability, it inevitably brings ethical challenges, such as misinformation, copyright infringement, or impersonation. I'm optimistic we—as users—will navigate these responsibly, but it's definitely a conversation we need.
A side note. This trend of reducing model restrictions and giving users more control - started with the release of Grok3, and publicly acknowledged by Sam during the interview with Ben Thompson - about what topics to engage or not is in my view a good thing. It’s treating users as responsible people rather than imposing one specific organization views, and once again, it’s born out of competition - Grok felt more natural to use > people start using more Grok > rest of labs respond. In my view, allowing users rather than organizations to decide what topics to engage with is a positive development.
The technology isn’t perfect yet. Despite its strengths, GPT-4o still has notable limitations. OpenAI acknowledges issues such as occasional inaccuracies in highly detailed or intricate images, difficulty accurately representing complex text elements in visuals, and challenges in consistently producing exact replications of subtle artistic styles or precise visual details —but hey, this is just V1.
In practice, these advancements translate into lower user frustration and improved accessibility. Within hours of release, everyone was already creating their own Ghibli-style avatars (myself included).
A new way to create content
My main argument in this post is that the key to the success of GPT-4o isn't necessarily superior to state-of-the-art diffusion models in image quality—it's that it combines sufficient quality (it’s really good, let’s be honest) with unmatched control and flexibility. Previously, using AI image generation meant randomness, typing prompts, and hoping for usable results—all my images were always like those "what you buy on Aliexpress vs. what you receive." GPT-4o changes this by generating images through predictable, step-by-step logic, similar to crafting coherent text. While diffusion might still have the edge for entirely original compositions, and thus will still have their audience, GPT-4o's autoregressive approach excels precisely where real-world applications thrive: iterative image editing and practical creativity, which is what the masses need.
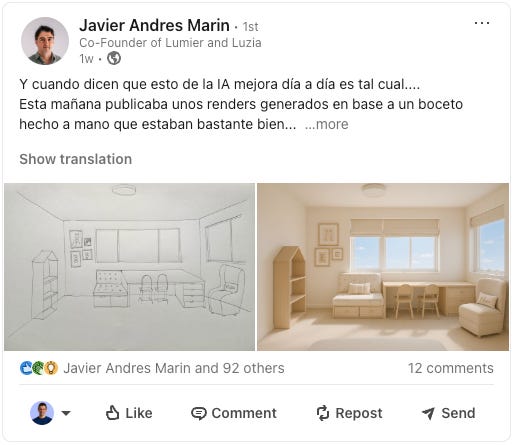
Imagine effortlessly transforming a hand-drawn sketch into a polished ad campaign, or quickly visualizing a new interior design idea. As Javier Andrés recently illustrated on LinkedIn, you could snap a picture of an outdated bedroom, quickly sketch your new vision, and let GPT-4o seamlessly turn that rough drawing into a stunning visual representation of your dream space.
Consider also the impact on advertising—imagine creating diverse, high-quality ads at scale, precisely tailored to represent your brand consistently. Similarly, envision crafting a rough, handwritten UI sketch and instantly refining it to a polished, high-definition prototype, drastically accelerating product development cycles.
You can also imagine hundreds of educational opportunities. Teachers can now transform standard lessons into visually engaging, customized infographics, making complex ideas easier to grasp. Imagine K12 educators easily creating interactive materials that not only explain topics clearly but also encourage students to explore concepts deeper than traditional textbooks ever could.
Or maybe… I'm overly optimistic, and we're just destined to flood our social feeds with charming Ghibli-style portraits.

Guilty!
P.s. OpenAI has not opened up these capabilities to the rest of the world, but we will continue working to bring them ASAP to Luzia users. Stay tuned
In all fairness, Google had released a similar feature a few days earlier, but it was limited to the AI Studio (developers only), and the quality wasn’t nearly as good as OpenAI’s.
Diffusion models leverage CLIP (Contrastive Language-Image Pre-training)—a model trained to connect text and images by converting prompts into embeddings—which serve as reference points that iteratively shape the entire image simultaneously.
We had access to an early release of advanced mode. That version was 10x better than the current one. The voice could replicate ambient sounds (e.g., footsteps, doors closing) and different voices within the same conversation. However, the excessive alignment put into that product has, in my opinion, killed it.