
And AGI Went By. 2026 the Year of Boring AI
2026 predictions: models commoditize, loops win, and the real progress gets harder to screenshot.
We won’t remember 2025 as the year of AGI, and yet we crossed the holy-grail benchmark that has haunted the AI field for 75+ years, with weirdly little fanfare: the Turing Test (1950).

Not the “two-party, I’m chatting with a bot and I know it” version. The original version: a three-party imitation game, where you chat with a human and a machine at the same time and you have to guess who is who. In the UCSD study (March 31, 2025), GPT-4.5 was judged to be the human 73% of the time when prompted with a human persona. That’s not “it sounds good.” That is “it beats actual humans at seeming human.”
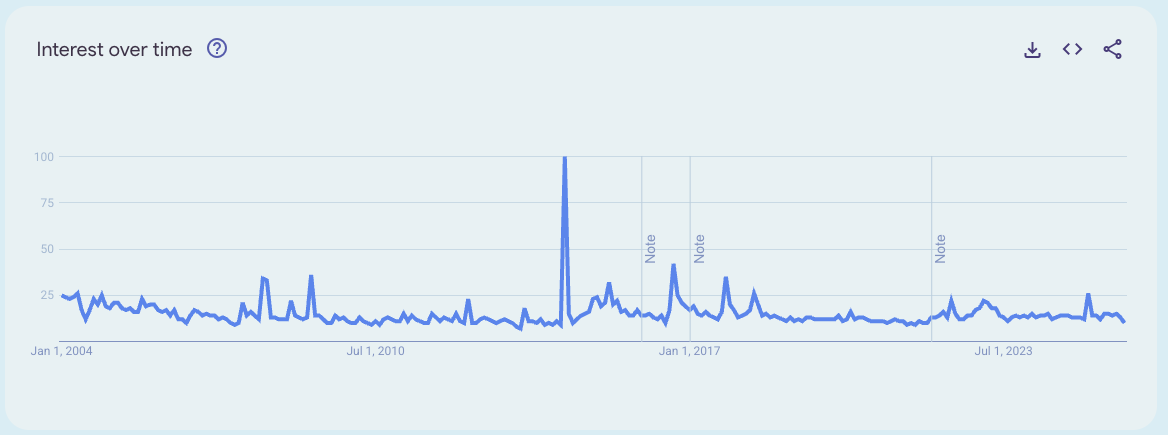
2025 was also the year the new models saturated most of the hardest benchmarks (industry jargon for “we ran out of signal”), including ARC-AGI (the #2, because the #1 was supposed to be AGI, but we already ruined that word).
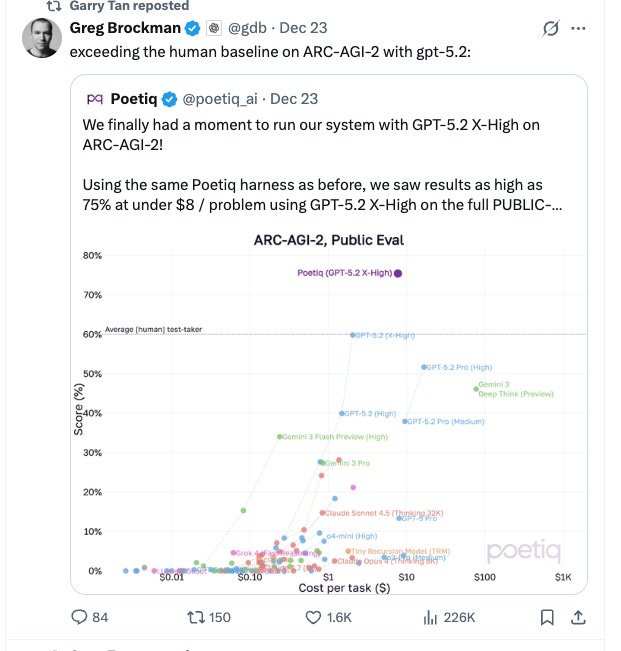
Leaving for 2026, we still have hope in the humbly named “Humanity’s Last Exam”.
So why am I talking about 2025 in a 2026 prediction post?
Because, as I did in my 2024 and 2025 posts, I’ve decided to be 100% correct. Meaning: 10/10 predictions. I’ll do it using two advanced techniques:
I’ll go to fundamentals so we talk about trends, not headlines.
I’ll attach probabilities to everything. If I say “90% chance” and it doesn’t happen, I was still right. I just taught you how to always be right on TV.
What are those fundamentals that will continue?
Jokes aside, 2025 was the year in which, as I argued in my Differentiation, Then Commoditization post, AI started to just work for many more use cases. A different question is what people actually use it for, but the “does it work?” debate stopped being the bottleneck.
We also pretended we forgot about model numbers (GPT-5.2?, Claude…?), which is obviously a lie because we are still terminally online. But something real did change: we moved from “wow, it can talk” to “shit it can do (parts) of my job”.
This simple illustration finally helped me visualize what’s going on. For the last 3 years I tried to picture AI as a concentric circle, my team has suffered countless versions of that slide in all-hands, but it never fully explained the weirdness. This does. The frontier is jagged. It can be insanely good at one thing and embarrassingly dumb at another, on the same day. And that jaggedness is basically the story of 2025.

The big unlock was not just raw intelligence. It was the combination of reasoning + tools + research workflows. Models got better at taking time, checking themselves, calling tools, reading sources, and producing something closer to an actual work product. Not just an answer.
Agents also went mainstream, mostly because models got reliable enough in verifiable domains, especially math and coding, where you can check outputs and run loops. This is also where reasoning actually cashes out. If you can verify, you can reinforce. If you can reinforce, you can build systems that feel like “agents” instead of demo magic.
Even Andrej Karpathy basically said “I feel behind” as a programmer
And we got the first real glimpses of “AI move 37” outside of games. Not “it wrote a poem,” but “it found something new.” DeepMind’s AlphaEvolve is a clean example: a Gemini-powered coding agent that searches for algorithmic improvements, including things that matter in real infrastructure, not just toy problems. You can call it early, you can call it narrow, but the direction is obvious: once the loop is there, discovery compounds.
Finally, 2025 was the year where I, and a lot of other people, ran out of ideas on how to test new releases. That is the key insight to understand 2026.
Because if you can’t even tell what got better anymore, it usually means progress is moving to places that are harder to observe from the outside.
2026: AI research and Application Layer take different paths
AI has theoretically unlocked extreme value in many areas. The paradox is that we are yet to capture most of it, and that is my main prediction for 2026.
While we will keep hearing about AI progress, there will be a split between AI research progress and application layer progress. Or said differently, two frontiers:
The public frontier will optimize for headlines. New benchmark records, new “state of the art” claims, new demos that look insane on X, and just enough novelty for money to keep flowing and consumers to keep trying the releases. Benchmarks have become marketing, which is fine, it is how the game is played.
The private frontier will be labs going back to fundamentals. Not because they became humble, but because pushing the frontier now requires more than “scale harder.” It is reasoning, training loops, verifiers, tools, data, and automating pieces of research itself. The stuff that compounds, but is harder to show on a leaderboard.
In this landscape, open source is the forcing function that keeps both worlds connected. It compresses the gap and makes “just wait for the next closed model” a weak strategy. It also erodes margins and pricing power, because once open weights are close enough, the enterprise conversation becomes “why are we paying for this.”
So yes, we will keep seeing progress everywhere. But it will feel weirdly bifurcated: the loud progress you can screenshot, and the quiet progress that actually moves the frontier.
Let’s see this thesis in detail.
AI Research Progress
1. Going back to lab work
While scaling laws have held in 2025 (more compute still tends to mean better models), improvements are harder to spot, and the capex to reach the next level is getting astronomical. The reasoning paradigm drove a big chunk of the gains, partly because it gave models something underappreciated: the ability to use tools in a reliable way. If you can plan, call tools, verify, and loop, you can turn “smart” into “useful”.
Compute-efficient companies (aka Google with TPUs) will keep brute forcing their way into better consumer models. The Gemini 3 launch is basically that thesis in product form: bigger is better.
The rest have a big bet to make: do we bet on ASI/AGI being achieved via generalization or via specialization?
Generalization means brute force the way to AI. Bigger generalist models that can do everything.
Specialization means automating the machinery of AI progress itself. Research loops. Verifiers. Search. Synthetic data. Systems that improve systems.
My 2026 prediction: all the AI labs will focus on specialization. Why?
There is enough room for value capture in the application layer that even if the frontier slows, we still have years of gains to ship.
Pure brute force is seeing decreasing performance per dollar, and the dollars are getting silly.
Specialization gives the best headlines for fundraising. Not “we trained a bigger thing.” More like “we discovered something new,” “we automated a chunk of research,” “we built a loop that compounds.”
And if I am right, that is bad news for the observability of progress. There will be two AI performance frontiers:
the one we see, focused on benchmarks, product demos, and application layer wins
the one we won’t see, focused on automating AI research and building training loops
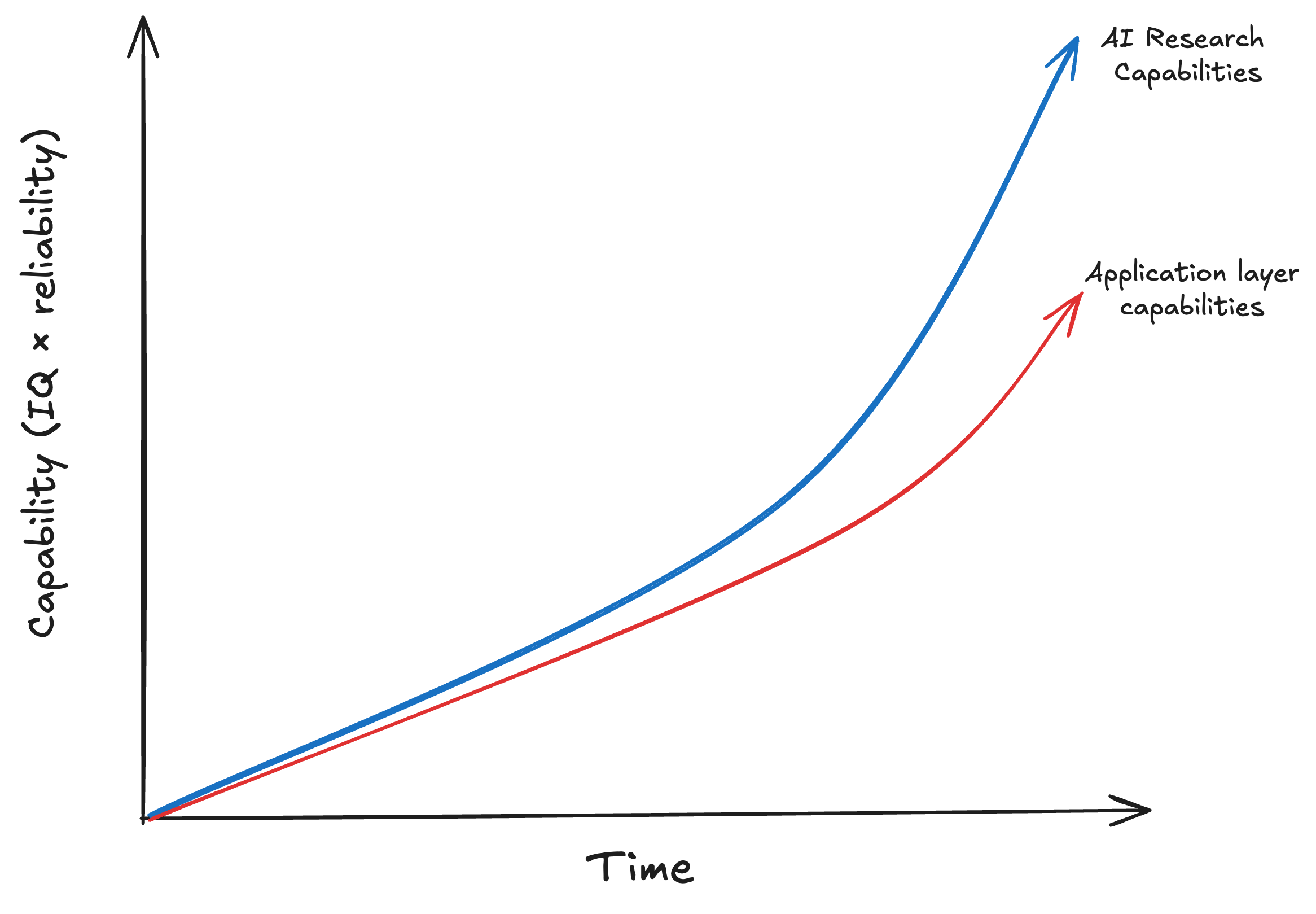
Conveniently, this prediction is hard to falsify. Which means I’m probably right.
2. The gigawatt age
Even if research is focused on automating AI research, bigger and more powerful data centers will be necessary to serve the growing demand for training, research, and inference. Given data center timelines (2–3 years), this is not much of a prediction for 2026. The prediction is the shape of the conversation: we will keep hearing crazier buildouts, and 2026 will be the year 1GW stops being a meme and becomes a real unit people use with a straight face.
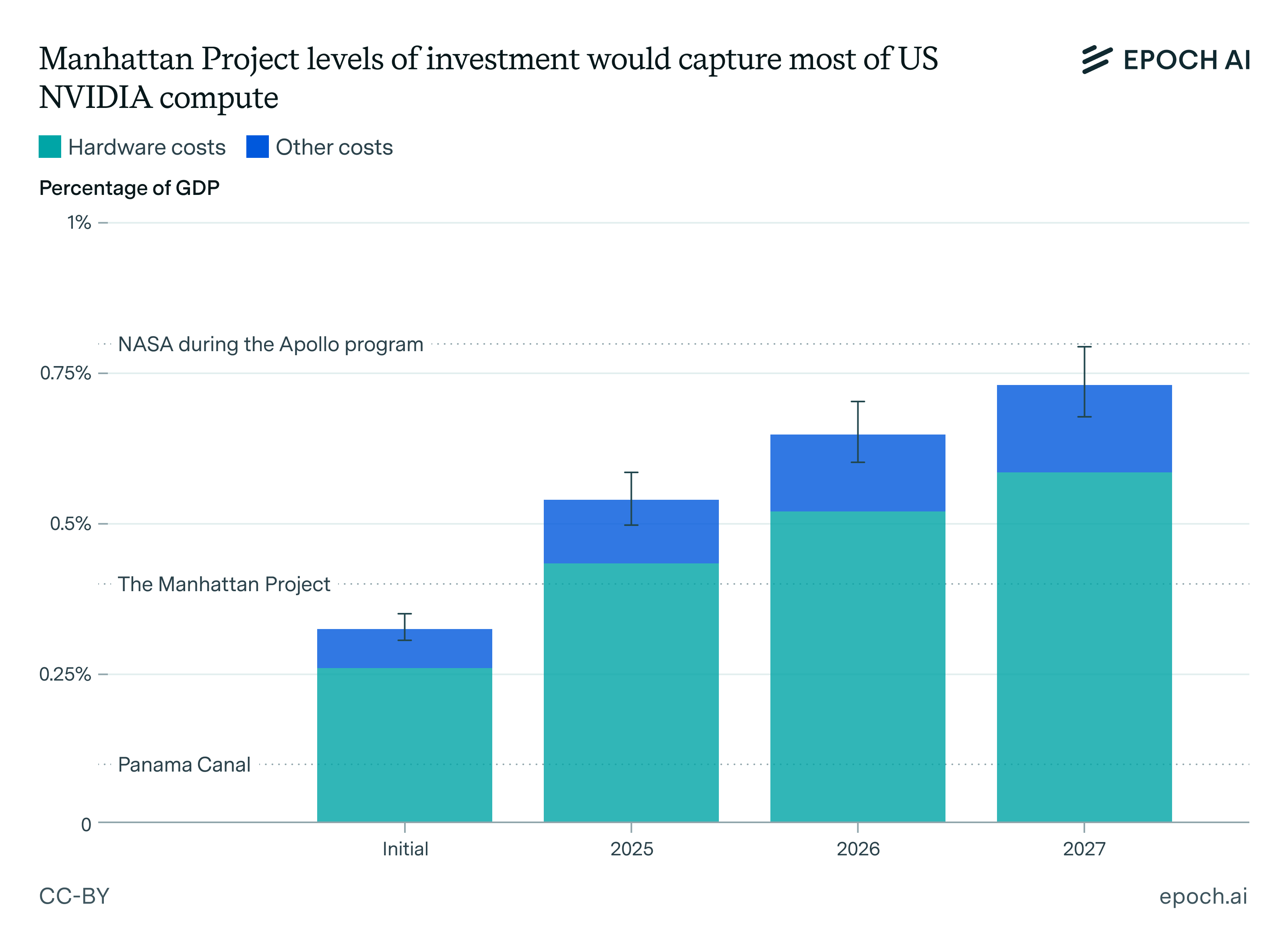
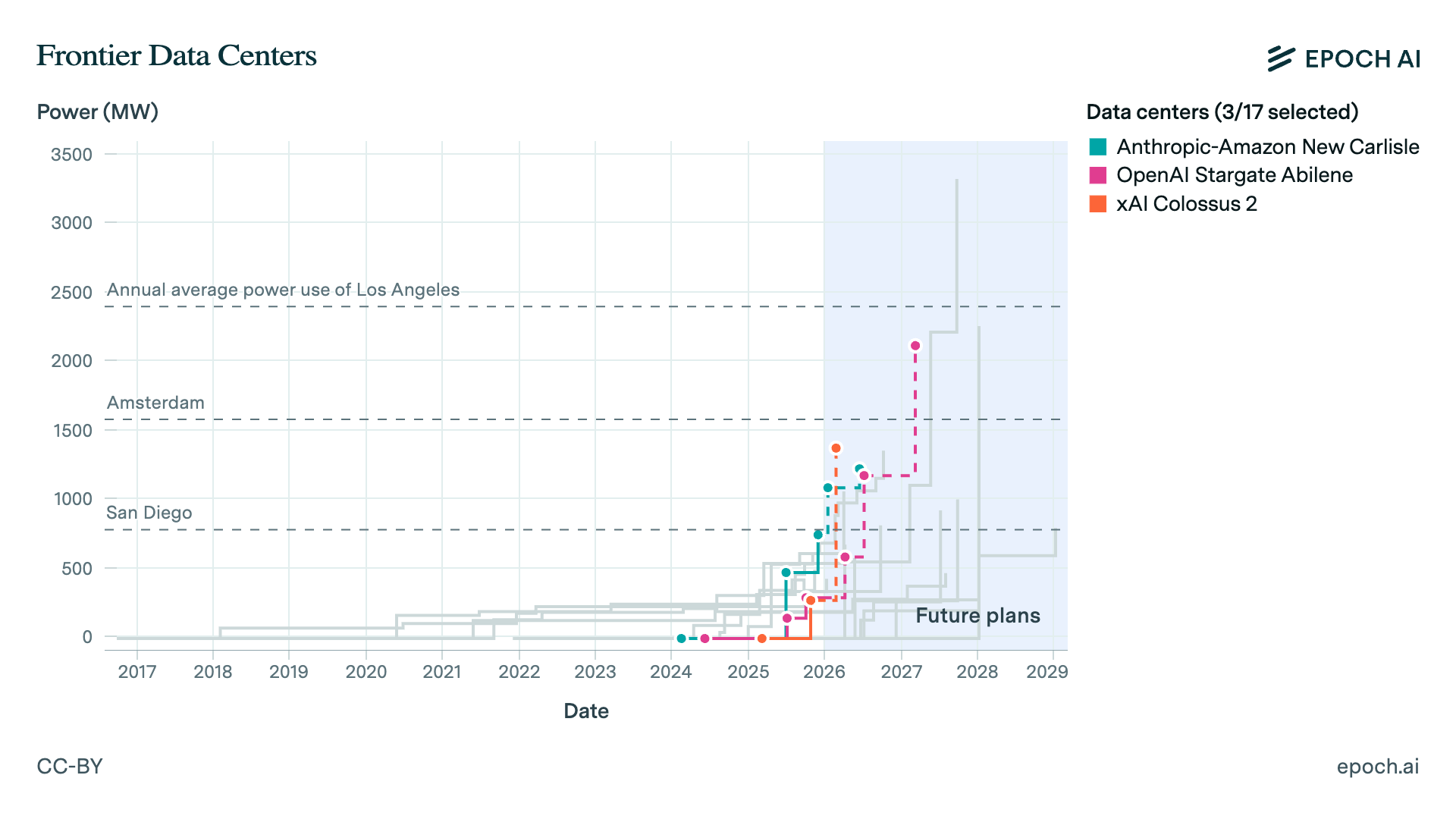
Industry has stopped talking about data centers as a function of “how many H100s,” and started talking about them as a function of energy provided, because energy is the bottleneck now.
Power becomes allocation: do you spend MW on discovery (research), scaling (training), or distribution (inference)?
My prediction is that this allocation problem becomes painfully explicit. Not in a philosophical way. In a budgeting way. In a “this site has X MW, we have to choose what it’s for” way. Altman’s point is the same: if compute is limited, you are effectively choosing what to prioritize.
My 2026 prediction: we will see at least one flagship data center openly framed as gigawatt-scale infrastructure, and the primary brag metric will shift toward efficiency, not just size.
Why? Because energy buildout has lag. You can’t spin up power capacity on a quarterly timeline. So the knob you can actually turn in 2026 is efficiency. That means the GPU story shifts from raw FLOPs to FLOPs per watt. Same capability, fewer megawatts. Or more capability inside the same power envelope.
This is also where the “two frontiers” idea shows up in physical form: the public frontier wants cheap, reliable inference. The private frontier wants enormous contiguous training runs. They both want the same megawatts. And in 2026, that competition becomes the main plot.
3. Reinforcement Learning from Verifiable Tasks
A bit of history here. ChatGPT was “only” a fine-tuned version of GPT-3, where via reinforcement learning from human feedback the model learned to talk like a product, not like a weird autocomplete. That small change started this revolution.
The next step (and most of 2025) was labs realizing something simple: if you can train against automatically verifiable rewards (like humans learning, did I do it correctly or not?), models start to develop strategies that look like “reasoning” to humans. They break problems into steps, they backtrack, they try different approaches, they learn to “work it out.” Karpathy explains it better than anyone, and he also makes the underrated point: RLVR ended up being high capability per dollar, so it gobbled up compute that otherwise would have gone to pretraining.
That also explains why math and coding jumped first. Not because those domains are magical, but because you can score them. You can run tests. You can check answers. You can reward correctness instead of confidence.
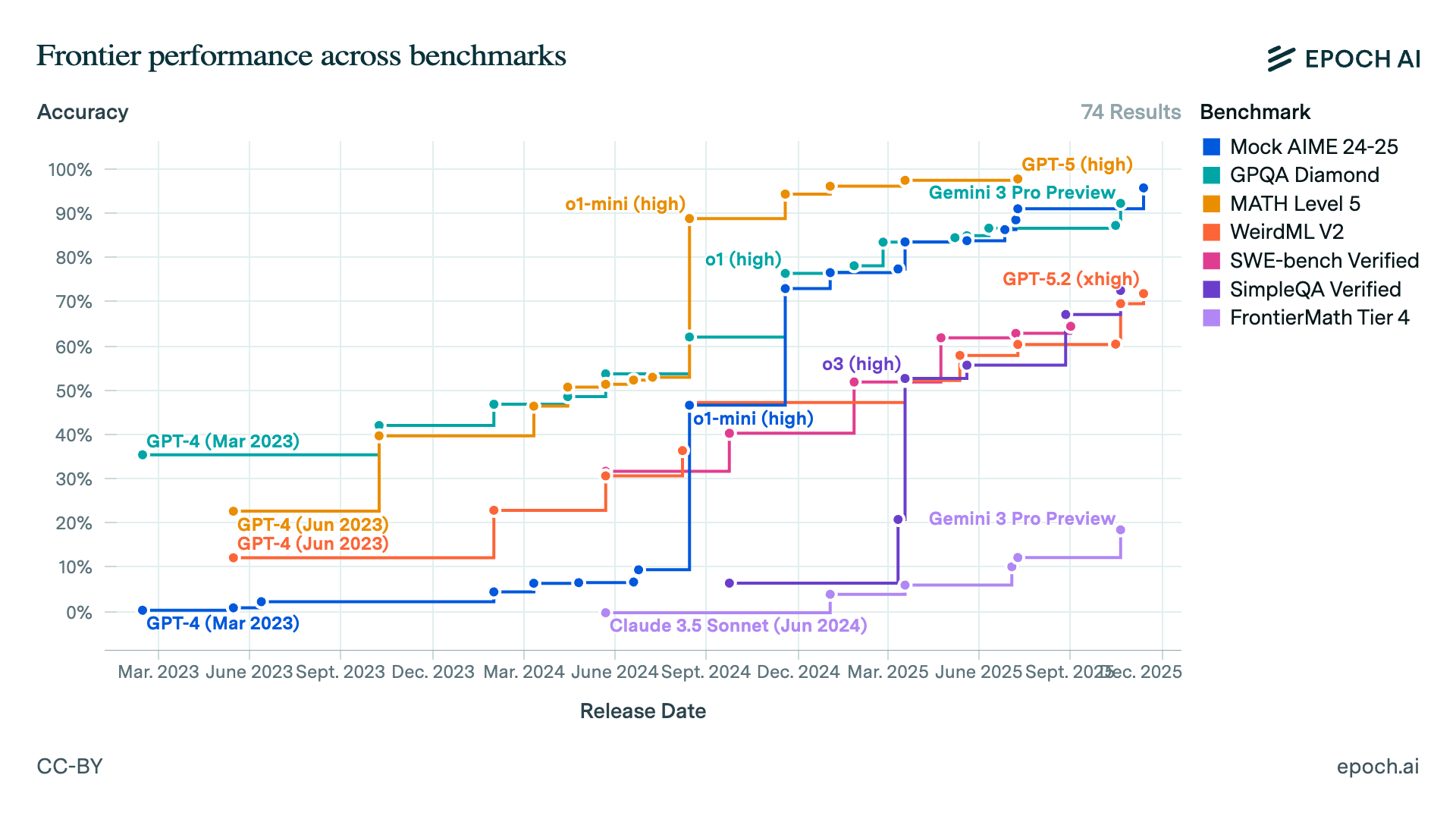
My 2026 prediction: verifiable loops expand beyond math and coding into messy real-world workflows—but mostly by turning the world into something scorable via tools.
This is the bitter lesson: you don’t need the model to become wise. You need the workflow to become checkable. Search turns “knowing” into “finding.” Code turns “thinking” into “running.” APIs turn “guessing” into “querying.” Logging turns “it worked once” into “we can measure it.” Once a task has a scoreboard, you can reinforce. Once you can reinforce, reliability stops being a vibes debate and becomes an engineering problem.
Now, you’ll see a clear bottleneck, if every new domain requires bespoke training environments (or fleets of robots1 grinding experience), bespoke tool sandboxes, bespoke reward functions, bespoke evals… then we’re not building “AI employees.” We’re building an industrial pipeline for teaching very capable systems a million narrow skills.
That’s not nothing. In fact, it’s probably the main way capability becomes usefulness in 2026.
If you buy the “loops-not-learners” framing, the obvious question becomes: where do we get cheap interaction data and cheap feedback? Because the real world is expensive. Slow. Risky. Full of edge cases you only discover by breaking production.
So if you can’t afford reality as your training loop, you simulate it.
Which brings us to world models.
4. World models for training loops and new data
In 2025 we saw the first really impressive world models. Some people saw them as a toy (cool games, cool videos). Others saw them as one of the missing pieces of the training pipeline.
In a few words, world models are AI systems that build internal, dynamic simulations of the world so they can predict how a world evolves and how actions change it. The key word is ‘closed loop’: you act, the world responds, it stays coherent, and you can keep going.
This is where the “verifiers” idea connects. Agents need environments. Environments create interaction. Interaction creates data. Data creates rewards. Rewards create reliability. And if real-world interaction is expensive or dangerous, a simulator gives you the loop without the cost.
If we were to get world models right, we could create useful environments to spin for training agents, other models, or even cooler, embodied AI (robots). These world models could be general (simulate a broad world, like Genie) or specific (simulate the physics of a narrow domain). We’re still far off, but to make it concrete: imagine we get a good enough driving simulator. The advantage of “collecting real driving data” shrinks, and the bottleneck shifts to “how good is your simulator.”
So far there have been two main research lines:
video generators (Veo, Sora, etc.)
actual world models (Genie-style closed loop)
Both are brutally expensive to train and run, which is exactly why this matters for 2026. If a lab can make a playable simulator cheap enough to run, it becomes a forcing function: suddenly you can train loops at scale, and suddenly “agent reliability” is not just a prompt problem, it is a data + loop problem.
")
My 2026 prediction: we will see the release of a playable, general world-model simulator by an AI lab other than DeepMind. Playable meaning: not just a video, but real-time interaction for minutes, where actions have consistent consequences.
My second prediction (more gambling): at least one frontier lab will publicly hint that synthetic data coming from world models is in the training pipeline. Not a full technical write-up, just the usual vague “we use simulators for training” line that makes everyone on X lose their mind.
And yes, this will matter for consumers too. Once models can “simulate” better, you get better physics intuition, better planning, better multimodal accuracy. It won’t just be prettier videos. It will be more useful systems. Next: downstream effects.
5. AI downstream effects
The most exciting and probably most bullish prediction is related to real world impact. I am preparing a longer write-up on this idea, but let’s start shaping it here.
The coolest thing about AI is not that it writes your email as a professional copy editor, or that you can ask for a website and get it in 10 min for less than $1 in cost. It’s that you have available intelligence from a tab. And once intelligence is cheap, the question stops being “what can the model say” and becomes “what can the model do.”
So here is my bullish 2026 take: attention shifts from “new model dropped” to “AI did something real.” Think a new AlphaFold moment.

I am intentionally picking biology here. Not because biology is easy (it is not), but because it has three unfair advantages for AI:
First, biology has a lot of structure. Under the mess, there are rules. Second, biology has bottlenecks that look like bottlenecks AI is uniquely good at attacking: search, pattern recognition, hypothesis generation, and synthesis across huge literatures. Third, and most important, biology has feedback loops. You can test things. You can run experiments. You can score outcomes. You can get closer to verifiable rewards than in most human domains.
So the prediction is: we will see at least one widely-visible, hard-to-dismiss moment where AI materially accelerates a biological pipeline. Drug discovery, protein design, wet lab automation, or a new class of biological insight that becomes a reference point.
Why do I think this happens in 2026?
Because, cynically, incentives. As Charlie Munger said, show me the incentives. We are building gigawatt-scale infrastructure. We are asking society to tolerate massive buildouts. And at the same time, most consumers can barely feel the difference between “model A” and “model B.” How do you justify the buildout when the average person thinks the main use case is rewriting emails?
You show a win that feels undeniable. A result that is legible to normal people. Something that makes the infrastructure story feel less like hype and more like a down payment on actual progress.
Application layer
If the private frontier is about back to labs, insane investments and verifier loops, the public frontier is better products that ship value under real constraints.
The models will keep improving, but the differentiator in 2026 is who turns that capability into a workflow that sticks. The app layer is the monetization layer of the split.
In B2B, the moat is workflow + data loops. In B2C, the moat is interface + distribution.
Enterprise workflows
OpenRouter’s State of AI report (worth reading, though a bit depressing to see the use case distribution) coined the “Cinderella / Glass Slipper” effect, which is a fancy way to name something very simple: once a model becomes good enough for a specific task, people stop switching. Retention locks in. The model disappears, the workflow stays.
This is the enterprise dynamic of 2026: the battle is not “who has the smartest model.” The battle is who owns the workflow. Who has the integration. Who has the permissions. Who sits inside the system of record. And who gets the data loop that makes everything better over time.
Because once you’re embedded, the good old SaaS retention dynamics kick in.
So here is Prediction 6.
6. Moats are the loops (enterprise edition)
In 2024–2025, a lot of enterprise AI was read-only: summarize, search, draft, suggest. It was useful (RAG systems finally started to work), but it still left the annoying part to the human: actually doing the thing.
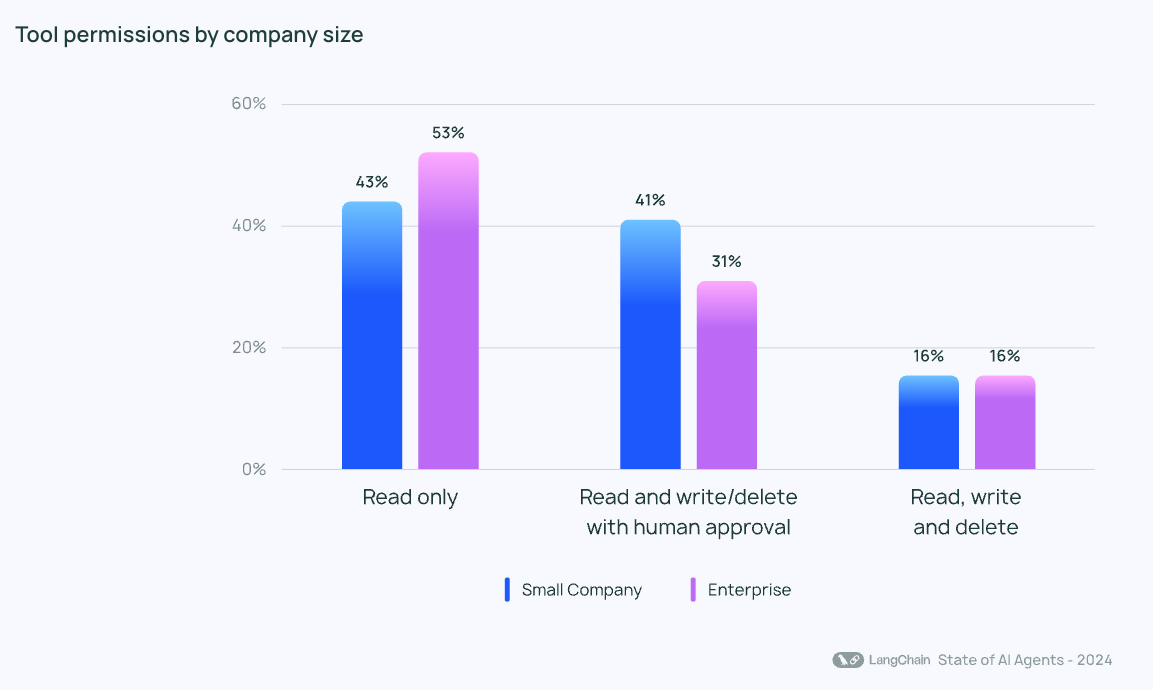
My 2026 prediction: approved write access becomes mainstream. AI stops suggesting and starts committing changes, with guardrails and audit trails.
That shift matters because write access is where the data loop becomes real:
when AI reads, you get productivity
when AI writes, you get automation
when you automate, you get feedback
and feedback is how systems get reliable
The gating factors are not model IQ. They are permissions, logs, rollbacks (as we spoke Claude Code just killed one Twitter demo repo I was working on!), and verification. If you solve that, agents stop being demos and start being boring, reliable automation.
7. Agents beyond coding and research
If 2025 was the year everyone discovered the word “agent,” 2026 will be the year we collectively admit the obvious: agents still fail too often.
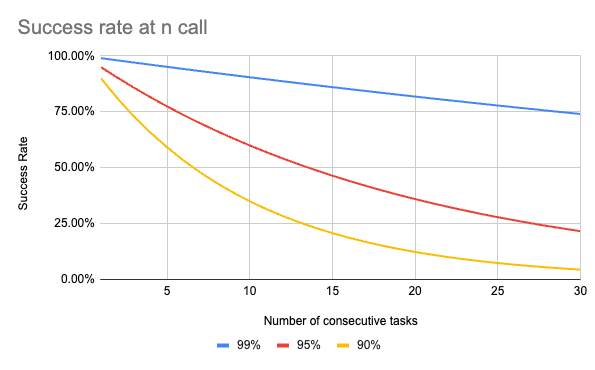
The problem is simple math, reliability compounds in the wrong direction. If a system is “95% accurate per step,” it feels great in a demo… until you ask it to do 10 steps in a row. Then your success rate collapses. Which is why most real products today either stay read-only, or they hide the agent behind approvals and guardrails.
So my 2026 prediction is not “autonomous agents everywhere.” My prediction is more boring and more real:
My 2026 prediction: we will see one general-purpose agent workflow outside coding/research become mainstream, but it will look like approvals + retries + audit logs, not autonomy.
The winning shape will be an “ops agent,” not a “CEO agent.” In other words, agents expand, but they expand where the work is verifiable and where failure is cheap. The pattern is the same as the rest of the post: loops win. Verifiers win. Guardrails win.
And this is also where the pricing story gets really weird. Models will keep getting cheaper per token (open source, routing, competition), but agents are token-hungry: more steps, more tool calls, more context, more retries (orders of magnitude not factors). So 2026 will feel like a paradox for builders:
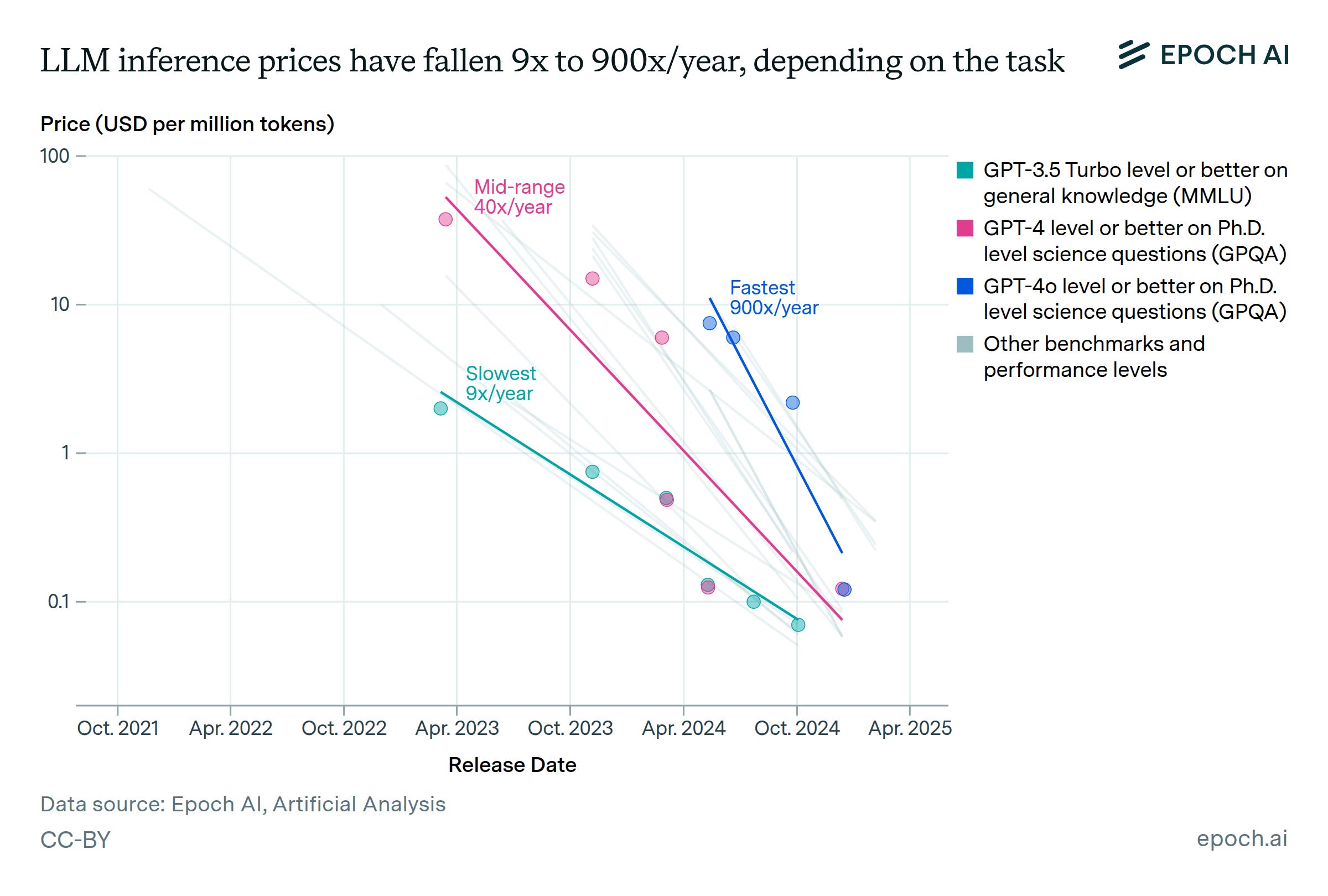
Prices per token go down, but cost per successful task stays stubborn unless you engineer the loop.
That is why the enterprise winners won’t be the companies with the flashiest agent demos. They will be the ones with the most boring system: evals, monitoring, permissioning, and a narrow set of workflows that run reliably 100 times a day.
A Bonus Prediction: The last 4 months of coding agents have been probably the craziest (and quietest) stretch of the last three years. Not because models suddenly got “smarter,” - which they did - but because they got reliable at the full loop. That is the difference between “autocomplete” and “junior engineer that never sleeps.”
2026 is the year the world realizes this. Not via a flashy demo, but the change of the default workflow for shipping software. Inside Luzia, my most productive backend engineers are already doing something close to the extreme version of that future. On some weeks, ~99% of the code that lands is AI-written.
Coding is the first domain where “agents” stop being a story and start being a baseline. Will that be the future for everything else?
8. AI Roll-ups
Why are we not realizing more gains from AI? Acemoglu’s main point: organizational bottlenecks - basically, we all struggle to change our defaults and ways of doing things. Then..
What’s the shortcut to see these productivity gains?
The shortcut is simpler: don’t sell AI to the incumbents. Buy the incumbents.
My 2026 prediction: roll-ups become a mainstream distribution strategy for AI in boring industries. People stop pitching “we built an AI for X” and start pitching “we bought X and made it 2x more profitable.”
A simple mechanism:
fragmented industries (a thousand small players, same playbook everywhere)
lots of repetitive work (admin, compliance, scheduling, quoting, claims, back office)
low tech adoption + low talent density (they cannot build this themselves)
AI can do a significant amount of the task (30-50%?) but not all (otherwise just sell the process!)
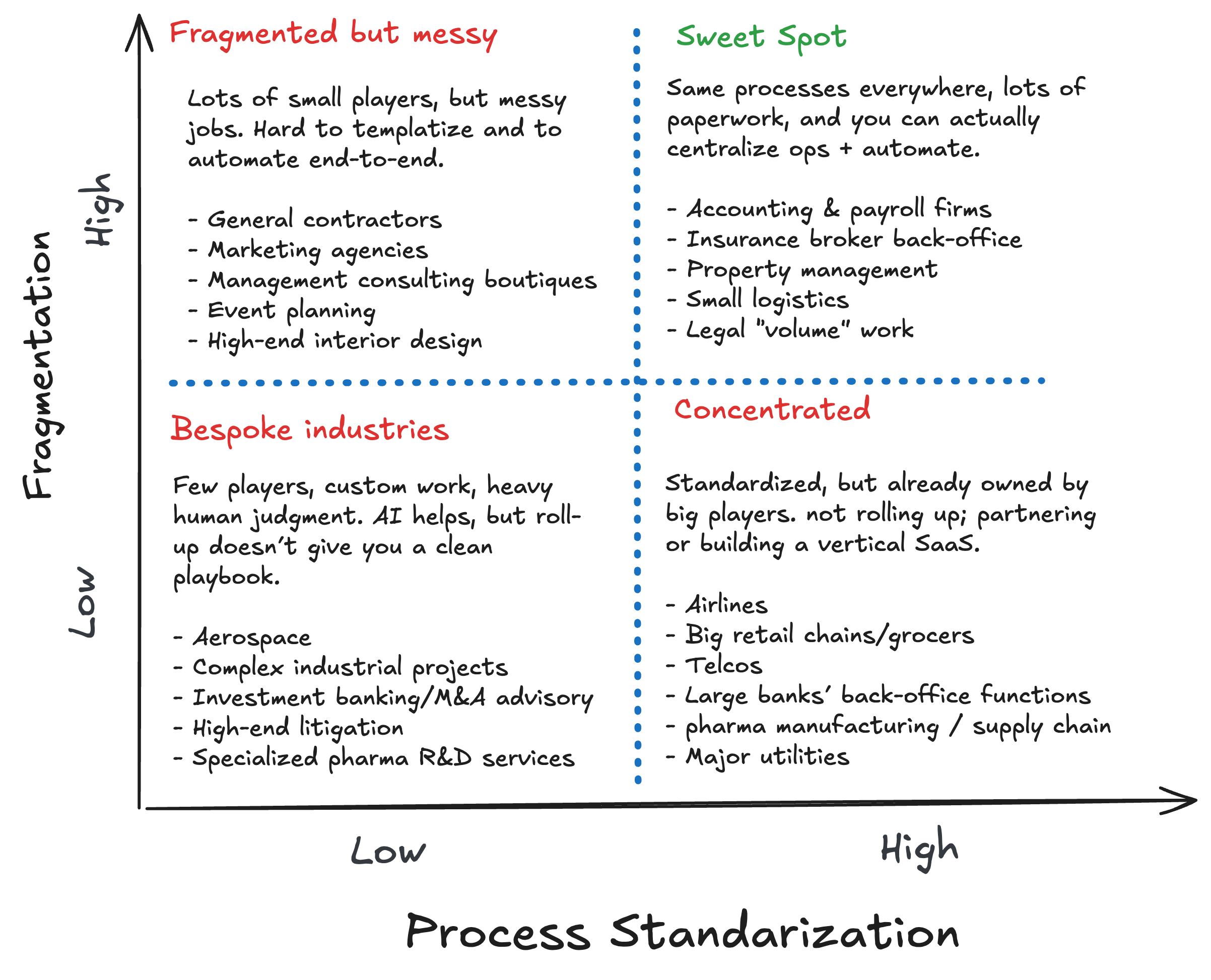
And here comes the loop again: buy distribution, create the training loop and see again prediction 6.
Cautionary tale: roll-ups show up in late-cycle moments, when cheap capital makes “buy growth” look like genius. Historically, acquisition waves can create real value, but they also create the same failure mode: integration gets postponed until the market stops forgiving you, culture hits you in the face, churn kills your client list.
Consumer habits
I have a strong conviction on the horizontal nature of AI, well beyond chatbots. As a horizontal technology, it will leak into almost all areas of our life. That will take time, and a ton of experimentation, and with winner-takes-most dynamics, the winners won’t be “best model.” They’ll be whoever nails the interface + distribution.
If B2B moats are workflow + data loops, B2C moats are habit + UI + quality perceived. And in 2026, UI becomes the battleground because models keep commoditizing.
9. AI will meet the real world in transactions
So far AI has mostly lived in the online world: write, search, generate, summarize. The online world meets the real world in one place: transactions. We already saw “agentic commerce” hype explode in late 2025, but my 2026 prediction: “agentic commerce” becomes boring. The breakout UX is AI + one-tap approval, not autonomy.
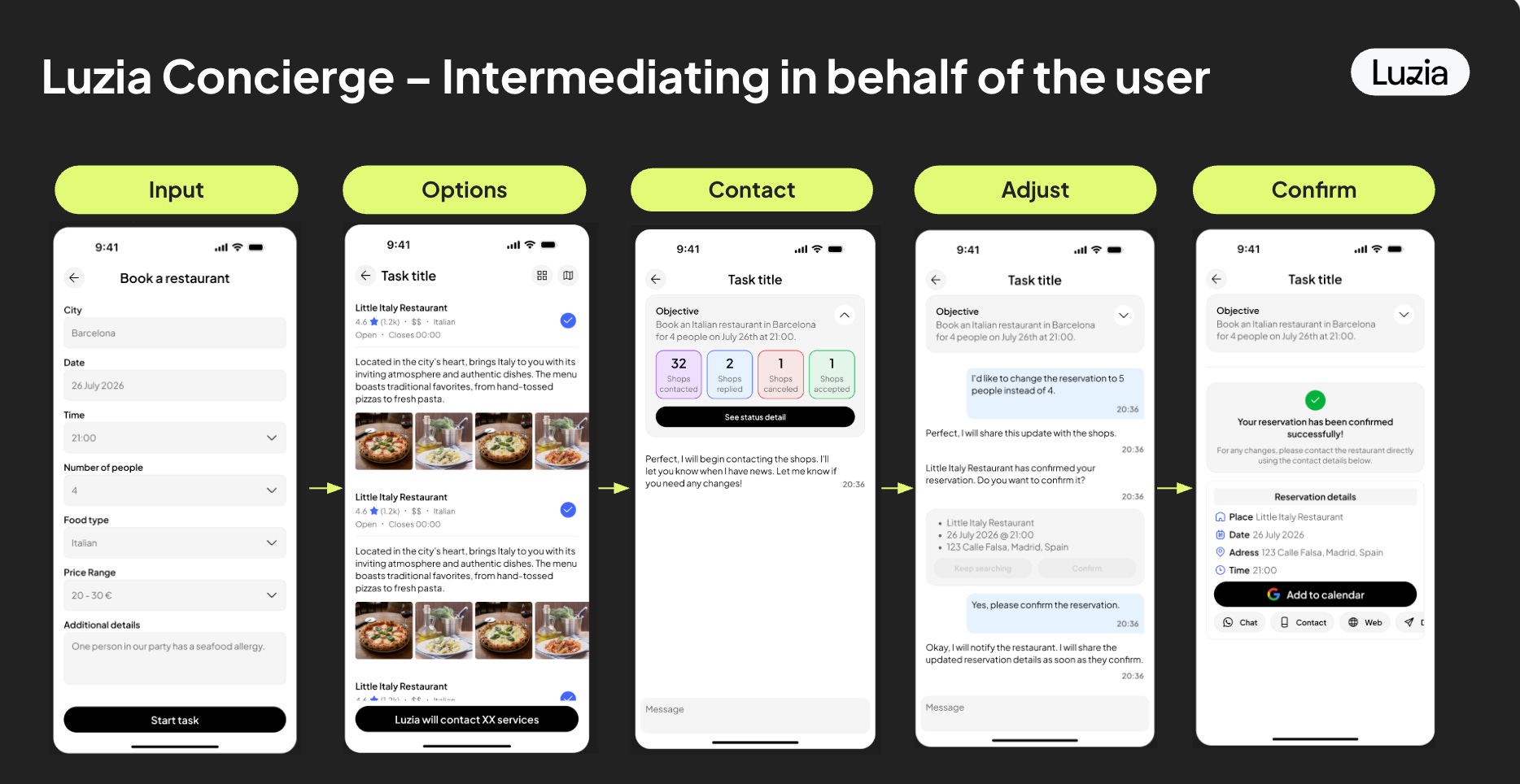
I wrote about the commerce side here: AI + e-commerce. And the local angle here: Local AI.
10. Image generation moves from aesthetics to application
2023 was “looks like a dragon.”
2024 was “look, I made a dragon.”
2025 was “look, I made a REALLY cool dragon, Ghibli style.”
2026 is “look, I made a useful infographic explaining the physics of dragon wings in low-density liquids, with labels that actually spell correctly.”

In short: from vibes → to work, with realism as table stakes. The edge in 2026 is realism + consistency + instruction-following + editing (the most underrated feature of nano-banana pro is “reasoning and the use of tools”).
My 2026 prediction: the breakout image workflows are boring (and useful) business workflows.
Product photos, menus, real estate listings, ads, catalog variation, customer-support visuals, compliance-friendly marketing and a lot of AI-slop in feeds.
The winning shape won’t be “blank canvas + prompt.” It will be first-step usability: templates, guided prompts, and one-click starting points that get you to a usable draft in 10 seconds. The generator becomes invisible; the workflow becomes the product.
And importantly: models stop being one-shot. The loop becomes: generate → edit → constrain → re-edit → keep character/brand consistent. That means:
Consistency becomes a killer feature: same character, same product, same brand style across 20 variations (aka the storyboarding / catalog loop).
Multi-step instruction-following actually matters: not “apply one style,” but “do three edits in order, keep X fixed, change Y, and don’t break Z.” Benchmarks like GenEval and T2I-CompBench++ are basically measuring this “can you follow constraints without breaking the scene” problem.
Text rendering + structured graphics go mainstream: the shift from “it spelled a word right” to “it produced an infographic / market map that carries dense information.” (This is where image becomes a document format, not just a picture.)

We can see glimpses of text rendering and structured graphics in Nano Banana Pro Editing is the primitive: image-in → image-out, not just text-to-image. If you can’t reliably edit an existing asset, you’re not in the enterprise budget. Datasets like MagicBrush exist for exactly that: instruction-guided edits you can evaluate. GitHub

This also ties back to world models. Better simulation and better “physics intuition” shows up as fewer impossible hands, fewer nonsense shadows, fewer objects melting into each other. Not because the model is artistic—because it’s less wrong about how the world works.
11. We will continue seeing attempts to crack social + AI
We will keep seeing “AI + social” launches, and they will keep looking obvious in hindsight: create content faster, remix faster, reply faster, flirt faster, meme faster. The supply side is solved.
The problem is the demand side. Social is not “content.” Social is status + identity + taste + inside jokes + timing. AI can generate infinite posts, but it still struggles to generate credibility. And without credibility, you don’t get network effects. You get a feed of perfectly fine slop.
So my 2026 prediction: we’ll see a lot of tries, some viral moments, and no durable winner. The products that “work” will be small, niche, and format-specific (one loop, one community, one vibe) and more importantly, obvious in retrospect.
The exception I can imagine winning is not a new social network, but an AI layer inside existing networks: better creation tools, better editing, better inbox triage, better “help me reply,” better community management or why not, more entertaining AI-slop.

12. AI that you don’t know is there.
My 2026 prediction: the best AI product launches next year won’t feel like “AI products” at all.
They won’t start with a chat box. They won’t ask you to prompt-engineer your life (and yet, now all companies are “teaching” prompting to their workers, again, organizational bottlenecks"). They will just quietly show up inside the workflow and remove friction: auto-fill the form, triage the inbox, summarize the call, draft the follow-up, update the CRM, route the ticket, flag the weird edge case, generate the asset variant, and move on.
This is the consumer version of the same thesis: as models commoditize, interface becomes the product. That has been my core thesis since Luzia started. Not “we have a model.” Everyone has a model. The question is: what UI shape turns capability into habit?
And 2026 is when we see the interface split into two winning shapes:
1) AI embedded inside existing products (invisible AI).
The AI layer disappears into buttons and defaults. “Smart reply” becomes “smart do.” Most users won’t even know which model is running. They will only notice that the thing got easier.
2) AI with a purpose-built GUI (visible AI).
The opposite of “one chat to rule them all.” Think NotebookLM or Luzia Tools style: a dedicated interface that constrains the problem, keeps context tight, and what’s even more important, makes clear what you can do with AI.

Don’t get me wrong, chats are here to stay - we drive most of our lives speaking! - but there is a lot more to AI than a chatbot.
Where both worlds collide: Open Source
A final take for 2026: open source is the forcing function that keeps the two-frontier world from breaking apart.
On one hand, labs want to go private: longer training loops, more verifiers, more tool use, more “automation of research,” more secrecy. On the other hand, they need revenue now: enterprise deals, consumer retention, distribution. Open weights compress that tension, because first to solve a use case wins retention (Cinderella is back”)
Open models make “wait for the next closed model” a weak strategy. Capabilities diffuse fast enough that the enterprise question becomes “why are we paying for this?”
That turns the model into a passthrough cost. The defensibility moves up the stack: workflow + integration + permissioning + data loops.
And it forces productization. You can’t retreat fully into private research if the “good-enough” option is closing behind you.
Open source is also the diffusion engine of the private frontier. Closed labs do expensive discovery, open ecosystems industrialize it, and the time window to extract monopoly rents shrinks.
And without entering geopolitics, pressure is not evenly distributed: China is the accelerant here. As I wrote in the past:
This looks like the Made in China 2025 playbook: pull as many workloads as possible into their stacks, learn from usage, starve U.S. counterparts of revenue, and, meanwhile, build the capabilities (chips, supply, know-how) to run the AGI race.
So here’s my open source prediction for 2026:
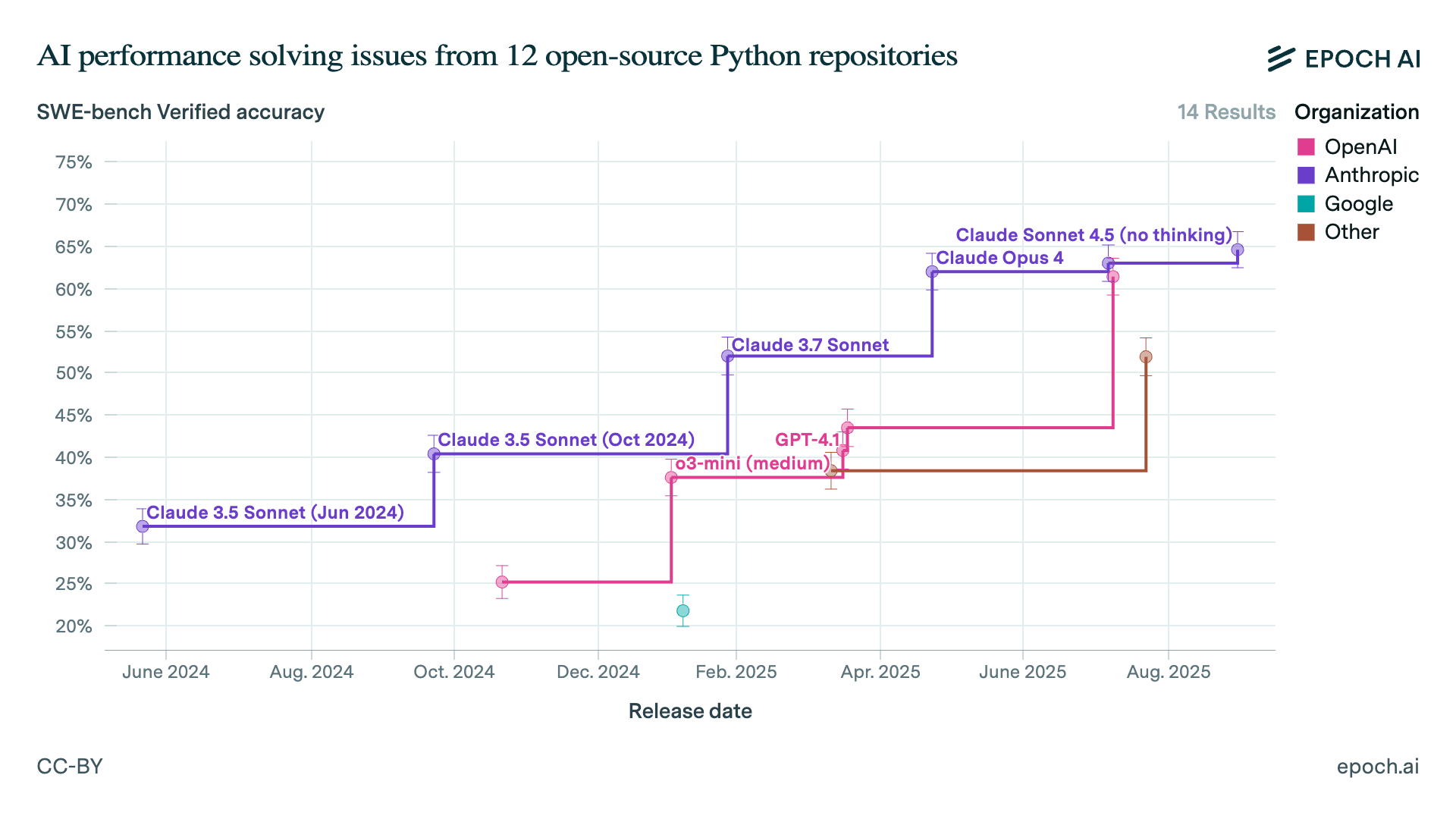
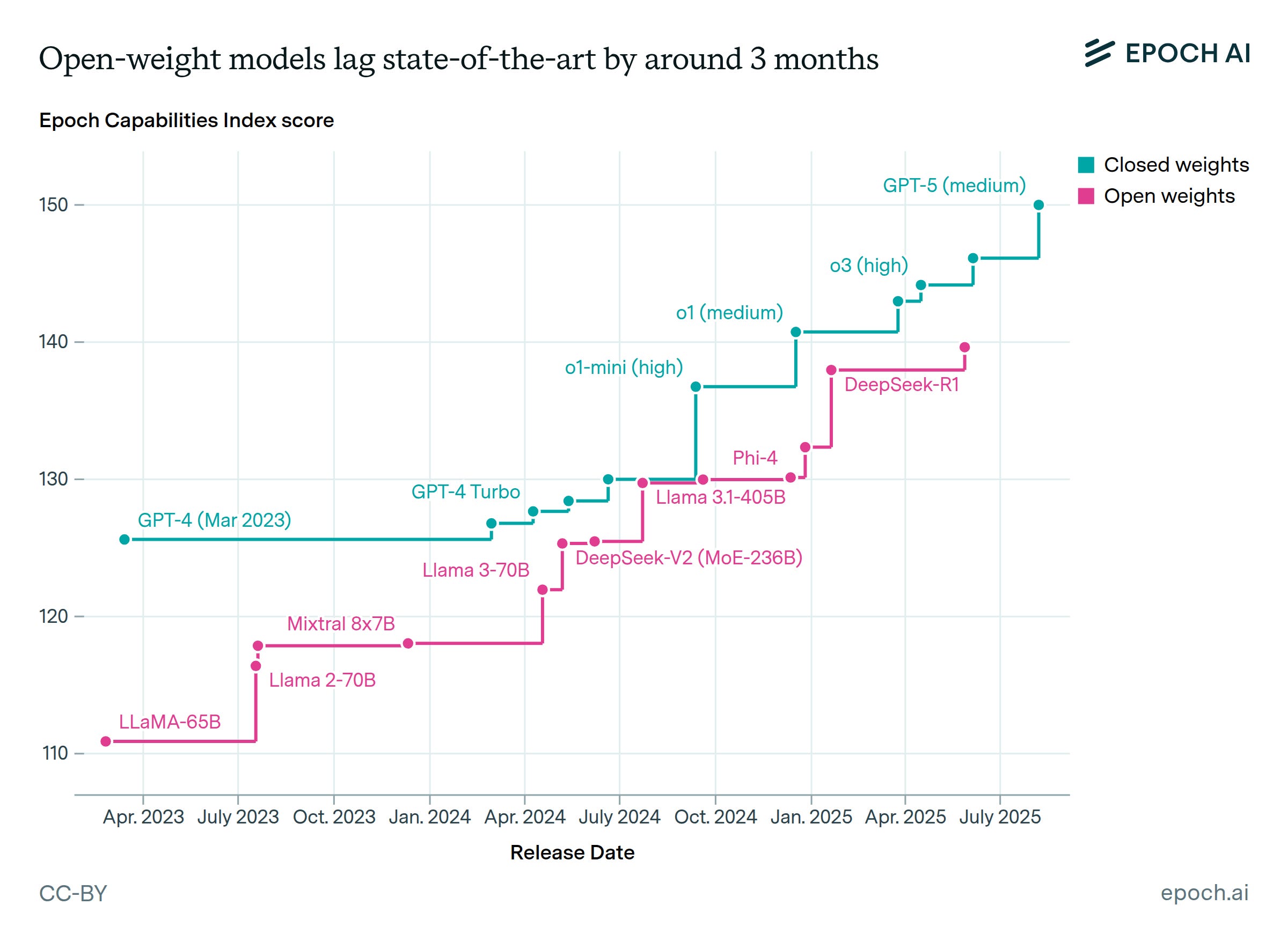
By the end of the year, the performance gap between open-weight models and closed frontier models stays around ~3–6 months for most enterprise-relevant workloads. Not because open source “wins,” but because the gap is now small enough that pricing power collapses unless you’re bundling a workflow people can’t leave.
Closing
Models stop being the story. Loops become the story.
We crossed the Turing Test without blinking, not because it didn’t matter, but because it didn’t change your Monday. The next wave does. Not as a “new model dropped” headline, but as a slow, irreversible takeover of workflows:
AI gets write access (with guardrails) and suddenly it’s not “helping,” it’s operating.
Agents don’t become autonomous, they become boring: approvals, retries, logs, and a few workflows that run 100 times a day without drama.
Discovery compounds where feedback is real (biology, code, simulators), and that’s where the first undeniable “AlphaFold-like” moments show up.
Open weights compress the gap enough that pricing power collapses unless you own the workflow people can’t leave.
So my summary bet: 2026 will feel less magical in demos, and more magical in outcomes. If 2023 was “talking,” and 2024 was “seeing,” and 2025 was “thinking,” then 2026 is the year AI starts doing.
See you in 2027. I’ll be 100% correct again.
This was a long one and I didn’t have space for robotics, but I suspect that with mostly functioning humanoid robots ready, we will soon start the data collection phase, and soon after that… the ChatGPT moment. 2027