AI Economics: Differentiation, Then Commoditization
Once a task crosses the IQ + reliability threshold, competition shifts from new capability to lowest-cost delivery — and power moves to whoever owns distribution and workflow.
Aug 13, 2025
My aha moment. GPT on laptop
The other day, I noticed something surprising. Two years after GPT-4’s debut, I’m running OpenAI’s GPT-OSS-20B on my two-year-old laptop. It uses about 3.6B active parameters, fits neatly in 16 GB, and scores around 85.3% on MMLU — basically early GPT-4 territory — but my only cost is electricity. No cloud bill, no GPU farm, no latency.
When an open-source model is “good enough” and runs on consumer hardware, the economics shift. In AI, that’s the moment the game changes: the control point moves from scarce, expensive capability to distribution and delivery.
Thanks for reading Alvaro Higes! Subscribe for free to receive new posts and support my work.
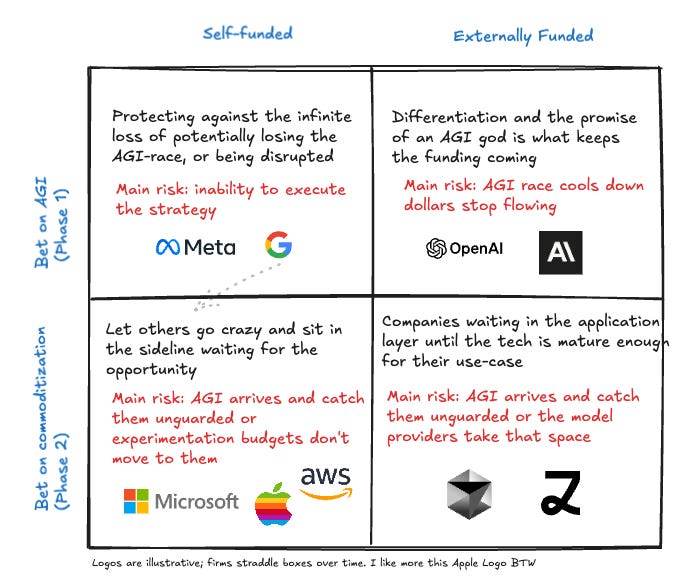
This isn’t new. Econ 101 says there are two ways to make money: differentiate, or be the low-cost provider. In AI, those map neatly onto two phases of the race. Phase 1 is about unlocking new jobs no one else can do. Phase 2, once those jobs are unlocked, is about serving them faster, cheaper, and more conveniently than anyone else.
GPT-OSS running in my two-year-old M3 at an amazing 33.65 tok/sec and TTFT of 0.43s
The rest of this post is about what happens when you cross that line — and why every advantage you hold in Phase 1 has an expiration date.
From Econ 101 to AI: two ways to make money
There are two sources of profit: differentiation and cost leadership. If you’re unique, you can charge a premium; if not, the low‑cost player captures most of the value. PCs in the 1990s moved from IBM’s high‑margin differentiation to commodity clones; smartphones show the split today (Apple integration and brand vs. Android OEM scale). I’ve argued before that models commoditize once a capability is widely available — the laptop moment suggests useful nuance.
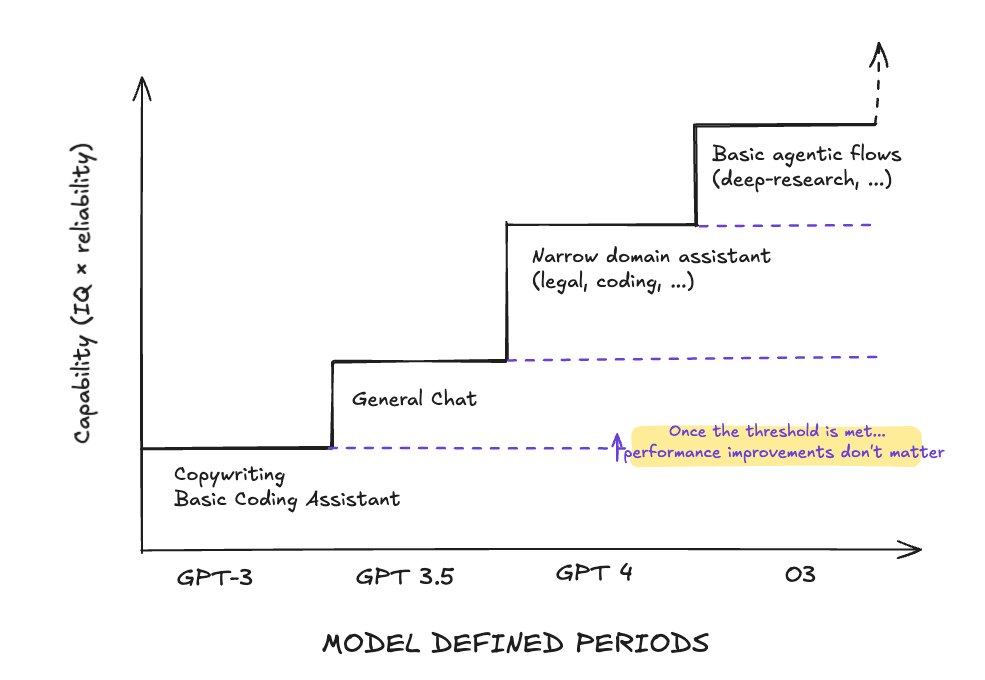
If we think about technology and AI as an enhancement tool- a bicycle for the mind in Job’s words - automation is the end game. For a task to be automated, three conditions need to be met: (1) enough intelligence; (2) enough reliability; (3) delivery at a lower cost than the alternative. Many everyday tasks — email drafting, summarization, boilerplate coding — sit just below this line. We can now do them reliably and cheaply with the existing models. Many other (sometimes not that complex) tasks are now within reach with frontier models (i.e., long-term memory, narrow domain agents…), while there is still a large group far from reach (i.e., AI research, autonomous reasoning for long periods of time…).
While seemingly not that relevant, thinking about what "good enough" means, and what happens when you clear the bar, has massive implications for how the AI market is shaping.
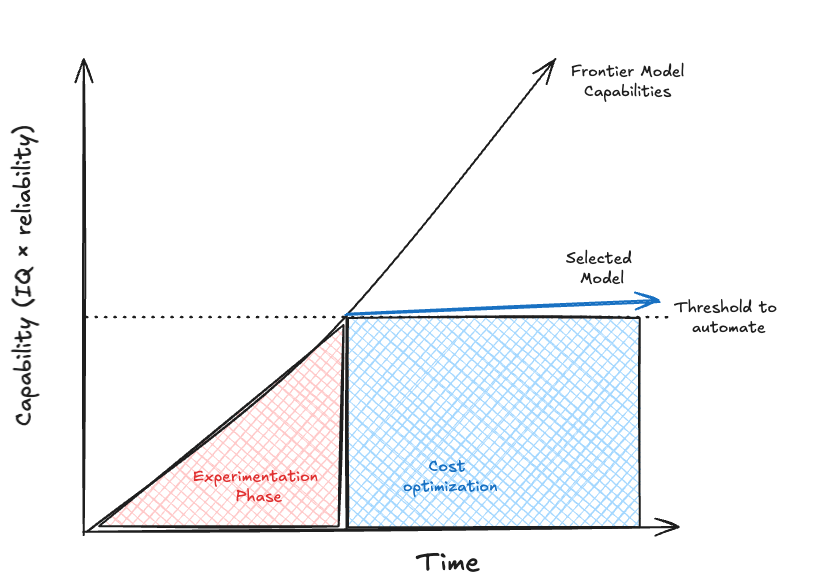
Phase 1: experiment until a model clears the IQ “×” reliability threshold. Phase 2: freeze the “good-enough” model and drive cost/latency down while the frontier keeps climbing elsewhere.
Reframing the AI race as a two-phase race
The automation threshold reframes the AI race into two distinct phases: phase 1 unlock the job (differentiation), phase 2 win on delivery (cost + distribution).
Each vertical step is a new job cleared (Phase 1). The flat that follows is diffusion (Phase 2), where cost falls and the category crowds and commoditizes. It is also a different way to look at our super simple framework.
Phase 1 — Differentiation (unlocking jobs)
Phase 1 is simple: clear the IQ × reliability bar for a specific job. When you do, you get paid because you’re the only one who can deliver it.
Before clearing the bar, you are in the experimentation phase, playing to see how much you can extract from the model. Clear the bar, and it stops being a demo—it’s an automation. Phase 1 is the fancy market position that breaks headlines, brings astronomical valuations, and burns billions of dollars.
Phase 2 — Commodity (serving jobs efficiently; the “good‑enough” period)
Once a job is unlocked, the advantage flips to cost and convenience. We have all been there. It’s nice to automate, it’s nicer if you do it as cheap as possible.
Since ChatGPT started the frenzy, no competitor has been able to really maintain a long-term technical differentiation lead. Phase 2 always comes. We have seen it with models—you can count in the hundreds the number of GPT-4 level models out there—and in the application layer where JTBD were quickly commoditized — copywriting, narrow domain assistants—
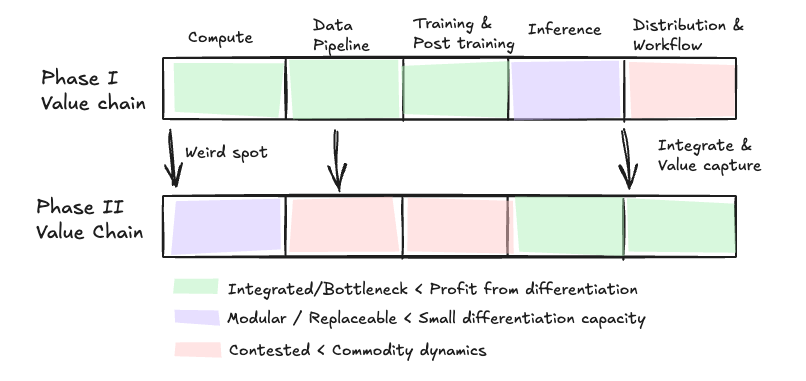
In short: a model launches, a category unlocks, then the crowd piles in and prices fall and then Christensen’s rule applies. Once the model is “good enough,” it modularizes and profits migrate to the new bottleneck. In Phase 2 the bottleneck isn’t the model; it’s distribution and workflow—owning where the work happens and the data + process + UX that wrap the model. The model becomes a replaceable part1.
Compute and training companies today (Phase 1) are the ones capturing most of the value, while inference providers and applications have thin margins. In Phase 2, compute, training, and post-training become commodities, and value shifts according to Christensen’s law of profit conservation. More here
Cloud (2006 → ). EC2 and S3 (AWS services) let startups run workloads they couldn’t on-prem. Containers and IaC then made those workloads portable. From there the fight shifted to price/perf—silicon, commitments, scale—and value moved from “who hosts” to “who wires hosting into the developer workflow.”
Windows (1990s → 2010s). Windows was the control point until the web—and later the cloud—pulled apps and data off the PC. Profits moved up the stack. AI will rhyme: once models are good enough, leverage sits in workflow and distribution, not in the model.
Lab‑by‑lab (through the two‑phase lens)
No-one can skip Phase 2. AI performance converges; the strategy is to monetize differentiation while building the lowest‑cost delivery machine for when capability spreads. Let’s see each lab where they are:
OpenAI — playing both games
Simultaneous Phase-1 (frontier) + Phase-2 (system-of-models/routing) strategy; finance depends on sustaining frontier narrative while pulling per-token costs down.
OpenAI is a strange mix: a category-defining consumer product (ChatGPT, probably worth a trillion on its own) and a frontier lab releasing some of the most powerful models. That forces a dual plan—keep unlocking new jobs (Phase 1) while industrializing delivery (Phase 2). The catch is financing: consumer ARPU and a commoditizing API won’t pay for city-sized training runs, so the AGI story is part of the business model. You need visible leaps to keep belief—and capital—flowing, even as you push routing and serving costs down. If AGI story fades, OpenAI is still a once-in-a-generation company, but not probably the one that everyone expects.
A Not Very Brief Note on GPT-5 release
OpenAI finally shipped GPT-5. Not a thunderclap, but a frikin good release—and cheaper to run. It’s a system, not a single model: a small classifier sends easy stuff to small paths and only escalates (with or without “think”) when needed. That’s pure Phase 2—routing for cost, latency, and reliability after Phase 1 unlocked the jobs. We’ve been doing this classifier→router setup for ~2.5 years; nice to see it at platform scale. Net: it just works, which is exactly what the market needs now.
Anthropic — the delicate one
Phase-1 coding beachhead; risk is rapid saturation → must deepen workflow (agents/tests) or broaden adjacencies.
Anthropic is the delicate one. They started on the OpenAI path (consumer + models), lost the broad consumer race2, and found a Phase 1 beachhead in coding—Claude 3.5 was genuinely great and really kickstarted the vibe-coding wave (Cursor/Lovable/etc.). The problem is that Phase 1 differentiation in coding seems even more ephemeral than that of other labs, so it works, until it doesn’t.
Open Source and other AI labs are aiming at coding, and competition keeps closing in, likely sliding Anthropic into Phase 2, but with big training bills and a thinner user base to finance the AGI plans (Amazon buys?).
Does anyone remember Inflection AI? Inflection AI was one of the OG AGI labs, trying to find differentiation through Emotional Intelligence. A valid hypothesis that did not find PMF, and as a result, the lack of consumer traction together with extremely high training costs resulted in the death of the company
In Anthropic world, the AGI hype - and the safety speech (we are the saviors of the world) isn’t optional; it’s the story that keeps capital flowing. Without it, they need to own more of the workflow (agents, repos, tests, policy) or the edge evaporates.
Google — distribution + cost + frontier (pick two? pick three.)
Hedge across frontier + distribution + low-cost serving (TPUs).
Google’s position is a hedge across both phases: frontier research (Gemini/Imagen/etc.), default distribution (Search/Workspace/Android), and low-cost serving (TPUs + data-center integration). Even without AGI, Phase 2 rewards the infra advantage and distribution. With AGI, Google has the compute, data, and channels to be a competitor in the race. Both routes being self-funded by the largest cash cow machine of history, Google Ads. The strategic challenge is product coherence: turning platform-wide distribution into habit-forming jobs while exploiting TPU cost curves and maneuvering a giant company with hyper-optimized margins.
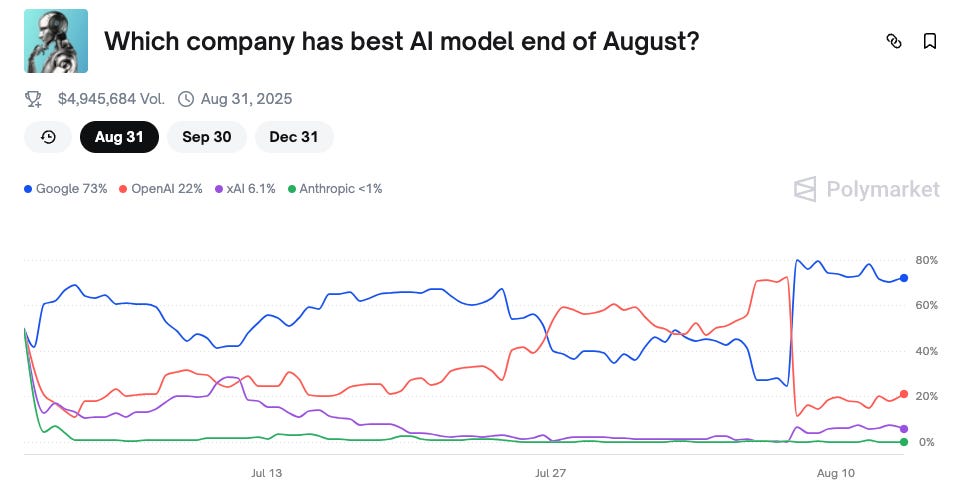
A visual representation of a comeback. After the launch of GPT-5, prediction bets on Polymarket for the best AI model surged dramatically in favor of Google. Source
Apple — the on‑device endgame
On‑device distribution turns Phase‑2 cost into electricity; privacy and OS integration lock it in.
Apple’s advantage is distribution on the device layer. From the outside, the strategy seems solid and aligned with the two-phase framework. Sitting out the hype while models shrink and quality improves to a point where on-device inference gives them an advantage — If only it was because that was the OG strategy and not the place where they found themselves after the disaster of Apple Intelligence. On-device inference pushes marginal cost to the user, reduces latency, and fits Apple’s privacy brand. The key is product framing: ship small models where they’re undeniably useful and capable (writing, summarization, personalization), and use private cloud only when necessary.
The biggest risk for Apple is that they continue making terrible bets, and even when the time comes that on-device inference is possible at scale, they miss the boat and either deliver an Image Playground v2, or worse, they are completely caught off guard.
Apple, I thought you could do better
Meta — accelerating Phase 2
Accelerate Phase 2 via open weights > spark Chinese competition > fall behind > founder mode > play catch-up
Meta’s play was to collapse differentiation across the industry by open-sourcing fast (leaking LLaMA, and releasing LLaMA 2 and 3). It worked: the market moved into Phase 2 sooner, where models are swappable and cost/distribution decide share. Chinese model companies were born. That conveniently aligns with Meta’s incentives: AI isn’t the destination, it’s the amplifier—more relevant feeds, more performant ad inventory, more ways to keep you in-app. The “AI Manifesto” reads like goodwill; the strategy is colder: make the model a commodity so nobody else owns the choke point.
And Meta can afford to wait. Recent AI stumbles aside, the cash machine keeps running ($18.3B of net income) and Zuckerberg is in founder mode, creating the AI version of “Real Madrid” so that if AGI arrives, they’ve kept a seat at the table; if it doesn’t, AI still lifts the core business. Either way, Phase-2 economics favor Meta’s strengths: ship fast, open-weight where it helps, and drive inference cost down so every surface quietly gets better—no need to chase a ChatGPT-level product.
Founder mode and a ton of cash to spare = a data center the size of Manhattan
AWS — the commoditization bet
Phase-2 cost and migration machine; win where the data already lives.
AWS was born to be the cheap, reliable place to run your jobs—swap out a hundred flaky in-house systems for one bill and decent uptime. Andy Jassy built that DNA - and a ton of technology, and it’s still the plan. They’re betting on Phase 2 - commoditization: everyone will need inference, not bespoke frontier workloads, and AWS already sits on most enterprise cloud spend. If Christensen is right, their advantage will be their position, many cloud loads are already in AWS. The play is obvious—soak up inference as it commoditizes—backed by tons of infra and their own chips (Inferentia and Trainium) to make serving really cheap (even if they trail Google on raw performance in their chips)
It’s a coherent strategy with one big risk: there are two other clouds, and AWS’s lock-in was a first-mover story. Do customers experiment with OpenAI/closed APIs and… just stay there? Or do they boomerang back once models are commodities? In case people stayed in OpenAI and the AGI race stays hot, AWS hedged a bit with an Anthropic right-to-match, meaning, AWS could put - a likely expensive - offer on the table to buy their ticket to the AGI table, but hey, same as Meta or Apple, they are sitting in a pile of cash.
Microsoft - Almost forgot about them
Rent the frontier from OpenAI; own Phase 2 via Windows/Office/Azure distribution and price/perf
Microsoft’s AI strategy is straightforward: rent the frontier from OpenAIand sell it through the distribution it already owns—Windows, Office, GitHub, Azure — via a very thin product layer (and copied features)
The unusual OpenAI–Microsoft partnership—Microsoft put up the capital and gets product and Azure upside—let Redmond “buy” Phase 1 while it wired Copilot into the stack. The bet is Phase 2: when models commoditize, price/performance on Azure and default placement in enterprise workflows matter more than model deltas. The biggest risk for them is similar to that of Apple AI. Thus far, Microsoft has not demonstrated the capability to release good AI products, with few to no hits. There is a chance that Phase 2 arrives, and they still get disrupted because of their inability to ship good products.
China — scale and price pressure
Made in China 2025, v2, with AI
After the DeepSeek January moment, China has been consistently shipping top-performing models across coding, images, text, and math. The strategy is clear: erode differentiation fast, the way Meta did, but without the red tape that slows U.S. firms. I’m also hearing from EU companies about inbound from Chinese clouds with very aggressive inference pricing. This looks like the Made in China 2025 playbook: pull as many workloads as possible into their stacks, learn from usage, starve U.S. counterparts of revenue, and, meanwhile, build the capabilities (chips, supply, know-how) to run the AGI race.
Is there space for small model providers and other competitors in the AI space? If so, what?
My bet is there is room for small labs and startups, but only where the model is a part, not the product: pick a narrow job-to-be-done, ideally local to your user (start where things don’t scale), integrate the base model with proprietary data and a tight workflow (ton of UI work here), and price the outcome, not the token.
Treat the model as swappable infrastructure, and build the moat around data, workflow, and where the user already lives.
Training costs and the long game
Frontier AI is a capital-allocation race: you either self-fund (Meta, Google), charge consumers (OpenAI?), or raise (OpenAI, Anthropic)—while unlocking new jobs faster than training costs rise. Training costs are outpacing unit revenues in many categories; that leaves two viable paths for the leadership of companies to justify crazy amounts of CAPEX expenditures: (1) Pascal’s-wager AGI—pay for a shot at outsized returns; (2) Compounding utility—unlock new automations fast enough that revenue growth beats CAPEX.
AI agents that work—firstly in narrow domains and later for general purposes—will unlock massive economic gains
Firms with durable cash engines or patient platform partners outlast pure-play labs, unless labs manage to keep the AGI hype up. Make Phase-1 money, build Phase-2 moats, and assume the control point keeps sliding to distribution—ultimately to the device.
In summary
The AI market is two races at once. Phase 1 is about unlocking new jobs by crossing the IQ × reliability bar; if you’re first, you earn rents. Phase 2 arrives fast:the capability diffuses, unit costs collapse (routing, distillation, better serving), and value shifts to whoever sits closest to the workflow—distribution, data, and UX—often ending up on-device for stable tasks.
Seen through funding: self-funded giants (Meta, Google, Microsoft, Apple) can wait out hype cycles and lean into Phase 2 economics—cheap, integrated delivery where users already work. Externally funded frontier labs (OpenAI, Anthropic) must keep the AGI story alive to finance ever-larger training runs while racing to industrialize serving so API price pressure doesn’t crush margins.
Strategically: make Phase-1 money while you can, but build the Phase-2 machine—routing, evals, reliability SLOs, and deep workflow hooks—because models become swappable parts. That’s where the control point moves, and that’s where durable profit will live.
Appendix. How AI labs differentiate and how to compete in cost?
Sources of differentiation
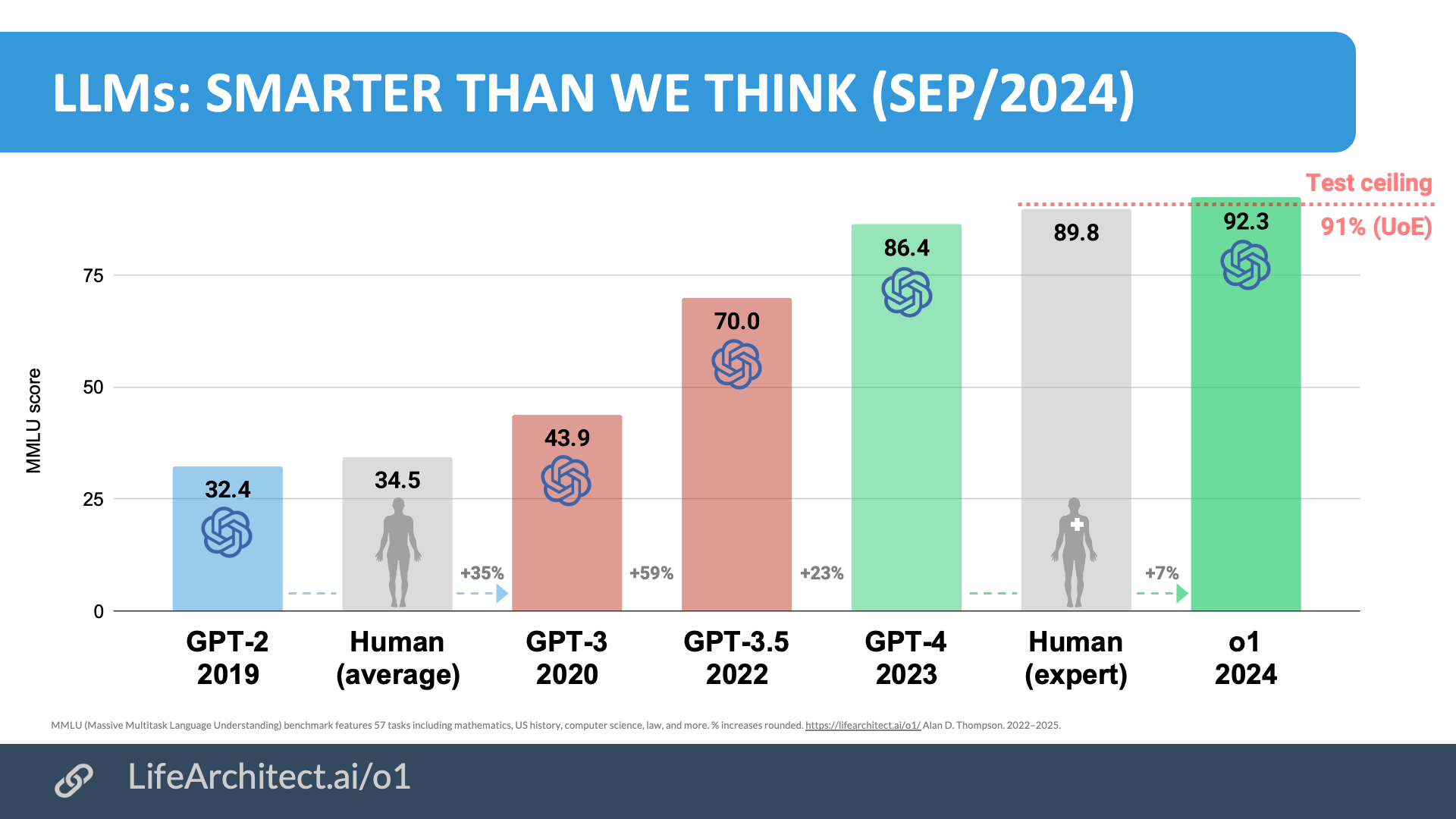
IQ — We have gone in two years from talking to models as smart as toddlers (GPT-2) to having unlimited PhD-level intelligence. That’s an increase in raw power and IQ, the type of increase that is (was?) predictable with the scaling laws (which I touched on here and here). This is what we mostly show with benchmarks. Improvements in raw power can be general, or can be domain-specific (law, healthcare, tool usage...)
An old visual representation of how smart models are and how fast they are progressing
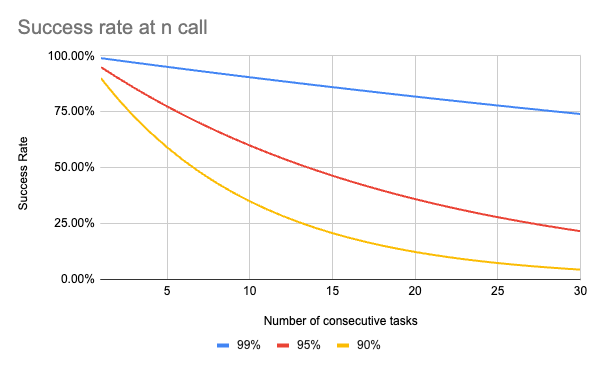
Reliability means correct results with consistency: minimal hallucinations, controlled failure modes, and predictable latency. In agentic flows — where a JTBD spans many LLM calls—steerability and low variance prevent error cascades. That’s the difference between a cool demo and a production service.
What seems like acceptable performance—let’s say 9 in 10 success—drops to 5/10 after only six calls, and to less than 1 in 200 after thirty calls.
Other (short-lived) sources of differentiation. We’ve also seen attempts to stand out via ultra-long context windows (million-token+, even 10M-token demos), new architectures (MoE, SSM-style variants), and whole new “reasoning” modes and tool use. They create daylight for a release or two, but so far none has held as a moat: the edge diffuses via knowledge sharing and model distillation.
How to compete on cost
How to compete on cost in AI could be the topic of several books, but I’ll try to group it into three routes: y
Architecture. There is a line of research on architecture that prioritizes efficient inference, enabling smarter token generation per model parameter. One of the most common is Mixture of Experts (MoE), which in short divides the model in sub-models specialized in different topics that are activated as needed. The other line of work for architectural improvements in efficient inference focuses more on improving cache usage.
Distillation & specialization. This is the process of distilling the capability of large models (IQ + dexterity) into small (sometimes specialized) models that can run very efficiently. Classic distillation still works; modern variants push reasoning into smaller models (see Let Them Think). This, at its core, is the technique that allows OpenAI and other providers to continuously improve the free plan.
For a given number of parameters—weights—there is a trade-off between model capability (IQ + dexterity) and model knowledge. If you want to create very intelligent yet cheap-to-run models, the model's core knowledge will need to decrease; they will be like smart kids who haven’t studied much, and the reverse is also true. This strategy—clearly followed by the OSS models from OpenAI—makes inference dependent on grounding, such as RAG, either from online searches or other sources, which, at the end of the day, passes the cost of inference to the user.
Hardware & systems. DeepSeek proved that you can always squeeze a bit more from a given TPU. Hardware optimization can come from two fronts: integrated systems, where models are custom-made for specific hardware architectures (think about the Google Cloud TPUs or AWS Inferentia 2); or optimizing the workload for specific machines (DeepSeek R0 for the Nvidia-H2O) or creating chips specialized in inference (groq).
On‑Device Is Phase‑2’s Endgame. When a task stabilizes, it migrates to the endpoint. Local inference collapses marginal cost to electricity and amortized hardware, improves privacy, and slashes latency.
The famous, not scientific pelican riding a bike benchmark. This is a progression from GPT 3.5 Turbo (end of 2023) to GPT-5 (summer 2025) with my computer running locally in the middle
For those reading from San Francisco, yup, they lost, no one uses Claude outside the U.S. As an internal reference, in Brand Awareness surveys, Luzia is 5x Claude/Anthropic in Latam